11 апреля, 23:58
Ученые оптимизировали большие языковые модели для работы на обычных устройствах



Forbes Russia
Для работы с ИИ больше не нужны мощные серверы Ученые «Яндекса» вместе с партнерами из ведущих научно-технологических вузов НИУ ВШЭ, MIT, KAUST и ISTA совершили прорыв в оптимизации больших языковых моделей LLM , узнал Forbes. Благодаря разработанному ими методу сжатия LLM без потери качества для работы с моделями будет достаточно смартфона или ноутбука. В условиях ограниченного доступа к графическим ускорителям GPU это может значительно упростить внедрение технологий на основе LLM в таких чувствительных сферах, как медицина, финансовые услуги и персональные ассистенты, считают эксперты. Подробности на сайте : Фото Getty Images


Хайтек
Исследователи из Яндекса, НИУ ВШЭ, MIT, KAUST и ISTA представили новый метод сжатия больших языковых моделей. Он позволяет запускать их на обычных устройствах — даже на смартфоне — без потерь качества и без необходимости в дорогом оборудовании.

Rozetked
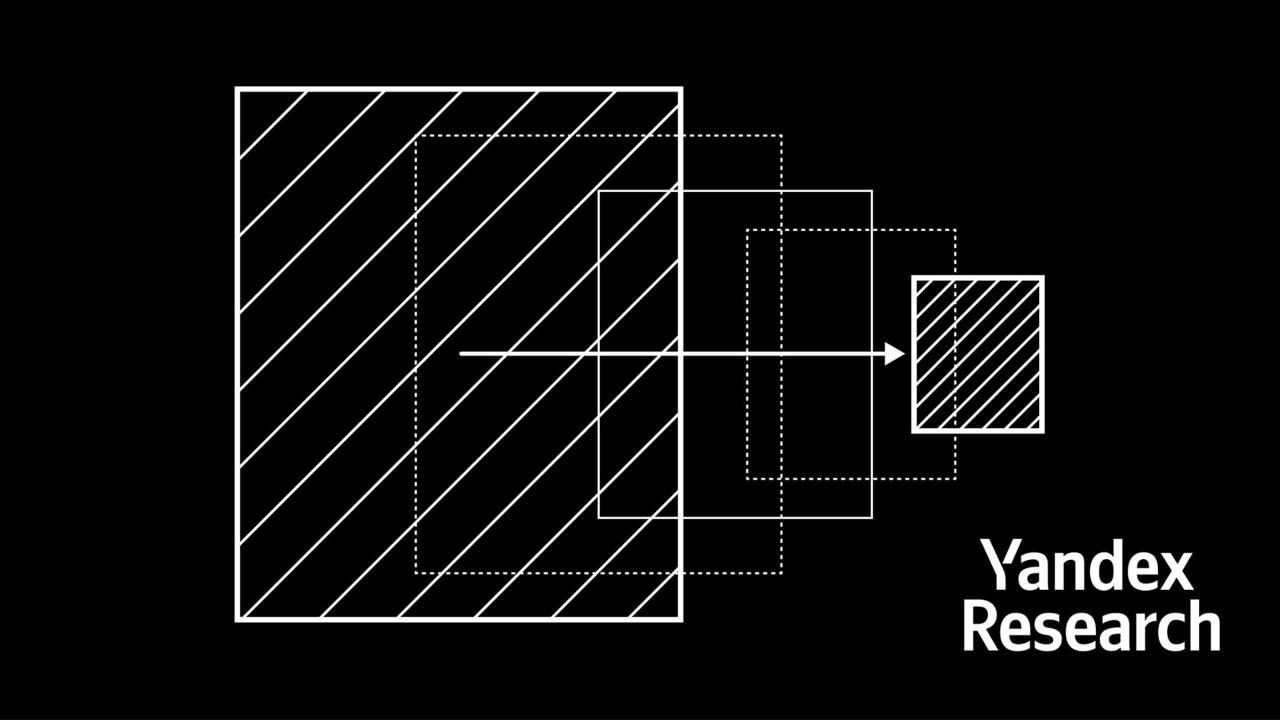
Учёные «Яндекса» совместно с ВШЭ и Массачусетским институтом разработали метод, который позволяет быстро сжимать текстовые нейросети без потерь Метод квантования больших языковых моделей получил название HIGGS. Он позволяет сжимать LLM без дообучения и сложной оптимизации параметров, так что это можно сделать прямо на смартфоне или ноутбуке. С помощью нового способа уже сжали гигантские DeepSeek-R1 и Llama 4 Maverick, которые помещаются только на специализированном серверном оборудовании. Где почитать и получить исходники HIGGS: rozetked.me/news/38679

НОП. Научно-образовательная политика
Исследователи из Yandex Research совместно с экспертами НИУ ВШЭ, MIT и другими ведущими университетами мира разработали уникальный метод оптимизации больших языковых моделей — HIGGS. Работа будет представлена на престижной конференции по обработке естественного языка NAACL 2025. Раньше, чтобы запустить LLM на обычном устройстве вроде ноутбука или смартфона, необходимо было квантизировать модель на мощном сервере — процесс занимал много времени и ресурсов. С помощью HIGGS этот шаг теперь можно выполнить локально и в разы быстрее — буквально за минуты. Метод открывает широкие возможности для сообщества open source. Даже модели с огромным числом параметров, например Llama 4 Maverick или DeepSeek-R1, становятся доступными для запуска без дорогостоящей инфраструктуры. Это настоящая находка для разработчиков, стартапов и небольших лабораторий, которым ранее не хватало мощностей для работы с LLM. HIGGS позволяет использовать компактные версии моделей, не жертвуя качеством, и уже демонстрирует лучшие результаты в сравнении с другими подходами — например, при тестировании на Llama 3 и Qwen2.5. Метод уже начал находить применение в академической среде — его используют Red Hat AI, а также университеты в Китае. #НОП


Yandex for Developers
Исследователи Яндекса сделали большие языковые модели доступнее Благодаря новому методу сжатия LLM можно сжимать на смартфонах и ноутбуках — без предварительной подготовки и с сохранением качества. Метод называется HIGGS Hadamard Incoherence with Gaussian MSE-optimal GridS . Исследователи из Яндекса работали над ним вместе с коллегами из НИУ ВШЭ, MIT, ISTA и KAUST. Научную статью, в которой описан HIGGS, приняли на одну из крупнейших в мире конференций по искусственному интеллекту — NAACL. Например, с помощью HIGGS можно эффективно сжать DeepSeek-R1 671 млрд параметров и Llama 4 Maverick 400 млрд параметров . Раньше такие большие модели удавалось квантовать только самыми простыми методами со значительной потерей в качестве. Метод сжимает нейросети без использования дополнительных данных и без вычислительно сложной оптимизации параметров. HIGGS экспериментально проверили на Llama 3 и Qwen 2.5 — оказалось, что по качеству он превосходит все альтернативные решения. Опробовать HIGGS вы можете уже сейчас на Hugging Face и GitHub. Если у вас оформлен Telegram Premium, поддержите наш канал по ссылке Подписывайтесь:

Наука и университеты
Российские ученые из Яндекса и НИУ ВШЭ совместно с MIT, ISTA и KAUST совершили прорыв в оптимизации LLM Лаборатория исследований ИИ Yandex Research совместно с Массачусетским технологическим институтом MIT , ВШЭ, KAUST и ISTA разработал метод HIGGS — новый способ сжатия больших языковых моделей LLM . Они представят его на одной из крупнейших в мире конференций по искусственному интеллекту — NAACL The North American Chapter of the Association for Computational Linguistics , которая пройдёт с 29 апреля по 4 мая 2025 года в Альбукерке, Нью-Мексико, США. Наряду с Яндексом в ней будут участвовать такие компании и вузы, как Google, Microsoft Research, Гарвардский университет и другие. Статью уже цитировали американская компания Red Hat AI, Пекинский университет, Гонконгский университет науки и технологии, Фуданьский университет и другие. Что уже известно? Квантовать модели вроде Llama 4 400B или DeepSeek-R1 671B теперь можно прямо на локальном устройстве смартфоне или ноутбуке — быстро, дёшево и с сохранением качества. Что это значит на практике? Раньше квантизация требовала дорогих серверов с GPU и занимала часы или даже недели. С HIGGS она происходит за минуты, без дообучения и сложной оптимизации. Это демократизирует использование LLM: : стартапы, научные команды, образовательные проекты и независимые разработчики получают доступ к тем же возможностям, что раньше были только у корпораций. Где узнать больше? Где можно ознакомиться с подробностями? Метод HIGGS уже доступен разработчикам и исследователям на Hugging Face и GitHub, а научную статью про него можно прочитать на arXiv. Чего ожидать дальше? ИИ уходит от имиджа сложной технологии и становится гибким инструментом. Новый способ квантизации даёт больше возможностей для использования LLM в различных областях, особенно в тех, где ресурсы ограничены — например, в образовании или социальной сфере.


42 секунды
Forbes: Для работы с ИИ больше не нужны мощные серверы – Ученые Яндекса и партнеры совершили прорыв в оптимизации LLM – Метод быстрого сжатия LLM работает без потери качества модели – Партнерами Yandex Research были вузы НИУ ВШЭ, MIT, KAUST и ISTA – Теперь для работы моделей достаточно смартфона или ноутбука – Использовать дорогие серверы и мощные GPU для LLM не требуется – Метод позволяет быстро внедрять ИИ, экономить время и деньги – Его назвали Hadamard Incoherence with Gaussian MSE-optimal GridS – Новый метод сжатия LLM может изменить правила игры в мире – Использовать мощные LLM можно будет на обычных устройствах – Это поможет небольшим компаниям, стартапам и исследователям – HIGGS ускорит процессы разработки, тестирования и внедрения – Распределение тех. ресурсов будет демократичным и равномерным – Это особенно важно для регионов с ограниченными ресурсами – HIGGS способен сжать, например, большие R1 и Llama 4 Maverick – Речь идет про мощные модели на 67 млрд и 400 млрд параметров – Метод квантизации уменьшает их размер, сохраняя качество


Высшая школа экономики
Большие языковые модели станут доступнее Теперь они не требуют мощных и дорогих серверов. Все благодаря разработке ученых «Яндекса», Вышки, MIT, KAUST и ISTA. Исследователи создали метод быстрого сжатия больших языковых моделей LLM без потери качества. Теперь для работы с моделями достаточно смартфона или ноутбука. Метод позволяет быстро тестировать и внедрять новые решения на основе нейросетей, экономить время и деньги на разработку. Это сделает LLM доступнее не только для крупных, но и для небольших компаний, некоммерческих лабораторий и институтов, индивидуальных разработчиков и исследователей. Подробнее о новой разработке рассказывает Вышка.Главное #ВНауке #НейроВышка


HATER.PRESS
Ученые из «Яндекса», НИУ ВШЭ, MIT, KAUST и ISTA разработали прорывной метод сжатия больших языковых моделей Лаборатория исследований ИИ Yandex Research вместе с коллегами из Национального исследовательского университета «Высшая школа экономики», Массачусетского технологического института, Научно-технологического университета имени короля Абдаллы в Саудовской Аравии и Австрийского института науки и технологий создала новый метод сжатия больших языковых моделей LLM , чтобы работать с ними на привычных устройствах — смартфонах и ноутбуках. Причем за считаные минуты и с сохранением качества. Это открывает доступ к передовым ИИ-технологиям для небольших компаний, стартапов и независимых разработчиков, которые не могут позволить себе дорогие серверы и мощные графические процессоры. Основная сложность в работе с LLM — их высокая требовательность к аппаратным мощностям.


Yandex for ML
Статья о новом методе сжатия LLM попала на NAACL Исследователи из Яндекса, НИУ ВШЭ, MIT, ISTA и KAUST представили новый метод сжатия LLM под названием HIGGS Hadamard Incoherence with Gaussian MSE-optimal GridS . Метод сжимает нейросети без использования дополнительных данных и без вычислительно сложной оптимизации параметров. Это позволяет запускать LLM на телефонах и компьютерах без дополнительного оборудования. Научную статью о HIGGS приняли на NAACL — одну из крупнейших в мире конференций по искусственному интеллекту. Вот всего два факта зато каких! про новый метод: С помощью HIGGS можно эффективно сжать DeepSeek-R1 на 671 млрд параметров и Llama 4 Maverick на 400 млрд параметров. Раньше такие большие модели удавалось квантовать только самыми простыми методами со значительной потерей в качестве HIGGS экспериментально проверили на Llama 3 и Qwen 2.5 — оказалось, что он лучше всех существующих методов квантизации без использования данных, в том числе NF4 4-bit NormalFloat и HQQ Half-Quadratic Quantization Мы надеемся, что HIGGS упростит тестирование и внедрение LLM, а ещё снизит порог входа в отрасль для некоммерческих лабораторий и институтов, индивидуальных разработчиков и исследователей. Опробовать новый метод сжатия вы можете уже сейчас на Hugging Face и GitHub. Подписывайтесь:
Похожие новости












 +4
+4









 +5
+5
OpenAI представила новые голосовые модели для улучшения диалогов и перевода в реальном времени
Технологии
14 часов назад В России разработана система ИИ для беспилотников и автоматизации авиации
Технологии
37 минут назад Российские продажи умных колонок достигли 1 млн единиц в I квартале 2026 года
Экономика
20 часов назад +456 российских компаний переходят на унифицированные коммуникационные платформы для цифровой трансформации
Технологии
1 день назад Модель Green VLA от Сбера завоевала золото на AgiBot World Challenge
Технологии
18 часов назад Обсуждение поддержки бизнеса и новые инициативы на ПМЭФ
Экономика
2 часа назад +5