10 ноября, 20:40
Google представляет инновационную архитектуру HOPE для преодоления катастрофического забывания в AI

Все о блокчейн/мозге/space/WEB 3.0 в России и мире
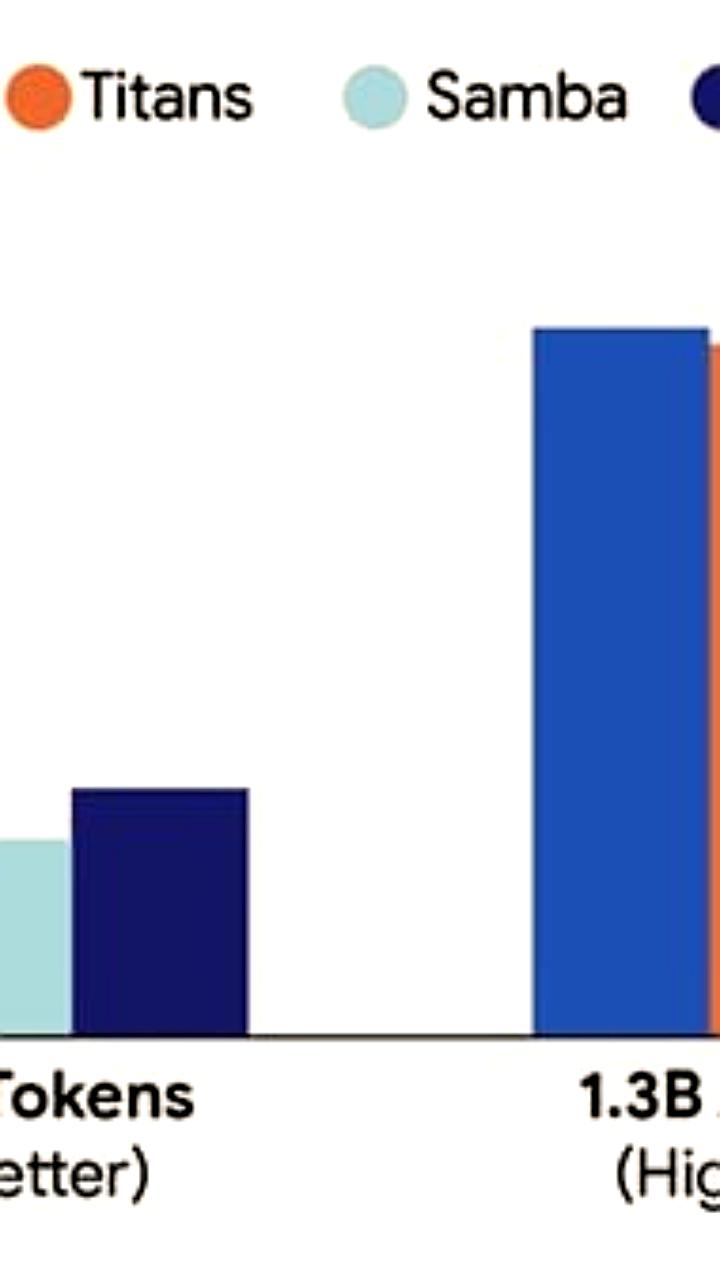
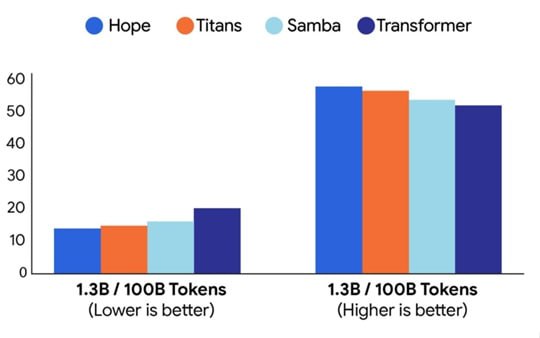
Ловите бомбу от Google Вложенное обучение Все как из фильма Начало Нолана Google Research представил Nested Learning которая решает одну из главных проблем современных моделей ИИ постоянное обучение Они доказали что архитектура модели и алгоритм обучения это одно и то же просто на разных уровнях Всё можно представить как вложенные задачи оптимизации которые решают одновременно Ключевые концепции Оптимизаторы это тоже модули ассоциативной памяти Память в трансформерах расширяется до Continuum Memory System спектр модулей памяти с разной скоростью обновления Идея взята из фильма Начало Нолана Каждый уровень живёт по своим законам и с разной скоростью времени верхний меняется за один токен самый глубокий раз в миллионы токенов Они создали модель Hope из 1 5 млрд параметров На данный момент она 3 е место среди всех моделей меньше 3 млрд параметров обходит Titans 1 8B Samba 1 9B RWKV 7B и даже Llama 3 1 8B по качеству языка держит 128 тысяч токенов контекста лучше Mistral 24B учится пяти новым задачам подряд и ни одну прежнюю не забывает Впервые в истории continual learning без replay без LoRA без regularization Просто потому что забывание побеждено на уровне архитектуры Какие нюансы Обучение на 35 дороже обычного Пока работает только в рекуррентных архитектурах В продакшене больших моделей пока нет Но уже есть три независимые репликации включая Mistral AI Nested Learning это новый фундамент Если идея взлетит через пару лет мы получим модели которые учатся всю жизнь как люди и никогда ничего не забывают

Обзоры IT Новинок и Исследований
Google учит ИИ не забывать Главная проблема современных нейросетей катастрофическое забывание Когда модель обучают на новых данных она нередко стирает старые знания Из за этого ИИ сложно доучивать без потери адекватности отсюда и забавные случаи вроде Байден всё ещё президент В Google предложили решение подход Nested Learning Он разбивает обучение на несколько уровней одни части модели обновляются часто другие почти никогда Так ИИ запоминает новое не теряя старое Прототип под названием Hope уже показал устойчивость и точность выше чем у трансформеров и современных RNN SSM подобных моделей Если метод приживётся появятся ИИ которые смогут учиться на лету не превращаясь в забывчивых студентов

2035. Новости НТИ
Памятная data ученые нашли способ побороть деменцию у ИИ Источник Известия Российские ученые предложили новую архитектуру памяти для ИИ которая повторяет принципы работы человеческого мозга Обучаясь нейросети постоянно забывают старые данные Такая деменция остается основным препятствием при создании беспилотных автомобилей или пожизненных медицинских помощников которым необходимо непрерывно подстраиваться под меняющиеся условия Специалисты подсмотрели принцип работы человеческого мозга и воплотили его в компьютерной модели что дало ИИ стабильные воспоминания Технология найдет применение в создании беспилотных автомобилей роботов и дронов полагают эксперты Как рассказал Известиям ведущий эксперт в области ИИ Университета 2035 Ярослав Селиверстов критически важной проблема забывания ИИ становится для автономных роботов которые должны накапливать опыт взаимодействия с объектами или для беспилотных автомобилей сталкивающихся с новыми дорожными ситуациями Это главный барьер на пути создания по настоящему гибких и самостоятельных машин способных эволюционировать подобно живому существу Вместо того чтобы равномерно обновлять все связи нейросети при обучении новая архитектура избирательно модифицирует только те синапсы которые имеют слабый вес и не несут критически важной информации Это напоминает механизм работы нашей памяти где новые воспоминания формируются не разрушая старые Заявленное увеличение продолжительности хранения информации в сотни тысяч раз выглядит революционным поскольку на несколько порядков превосходит возможности существующих аналогов сказал специалист В промышленной робототехнике такие системы позволят создавать универсальных роботов манипуляторов которые смогут осваивать новые операции с деталями не забывая предыдущие навыки сборки Для беспилотных автомобилей и дронов это означает возможность непрерывно адаптироваться к уникальным дорожным условиям или ландшафтам накапливая уникальный опыт без вмешательства инженеров Перспективным выглядит и их использование в персонализированных медицинских диагностических системах которые смогут эволюционировать вместе с историей болезни пациента или в умных домах гибко подстраивающихся под привычки жильцов рассказал Ярослав Селиверстов Нейросеть при обучении новой задаче иногда теряет до 90 99 точности в решении старых рассказал эксперт рынка TechNet НТИ гендиректор группы компаний ST IT Антон Аверьянов Эксперименты на простых задачах дают практически 100 ное сохранение старых знаний при использовании новой памяти Однако есть опасения связанные с тем что сегодня ни один из биологически вдохновленных механизмов не масштабируется на современные большие языковые или мультимодальные модели размером в сотни миллиардов триллионы параметров Но уже в ближайшие 5 10 лет это в теории можно интегрировать в малые автономные дроны и рои дронов которым необходимо работать годами без переобучения сказал Антон Аверьянов

Innovation & Research
Google представила Nested Learning архитектуру которая учится как мозг Google Research представила Nested Learning новый подход к обучению AI позволяющий моделям осваивать новые задачи без потери старых знаний Архитектура и алгоритм обучения работают как единая система вложенных оптимизаций с разной скоростью обновления Модель Hope с 1 5 млрд параметров уже входит в тройку лучших среди всех моделей объёмом до 3 млрд Она превосходит Titans 1 8B Samba 1 9B RWKV 7B и Llama 3 1 8B по качеству языка уверенно держит контекст объёмом 128 тыс токенов и осваивает 5 новых задач подряд без забывания Это первый пример постоянного обучения без использования механизма повторного воспроизведения replay метод адаптации модели с малыми ресурсами LoRA и регуляризации где забывание устранено на уровне самой архитектуры В основе Nested Learning лежит идея памяти как системы модулей с разной частотой обновления Быстрые компоненты реагируют на каждый токен а медленные изменяются лишь после миллионов шагов Такой принцип вдохновлён работой человеческого мозга где разные зоны действуют на собственных временных ритмах Hope показывает лучшие результаты в задачах с длинным контекстом языкового моделирования и логических рассуждений Она стабильно превосходит Mamba2 и TTT в задачах поиска нужной информации в длинном контексте needle in a haystack а по метрикам неопределённости модели и точности показывает лучшие результаты чем стандартные трансформеры Обучение модели обходится на 35 дороже она реализована только в рекуррентных архитектурах и пока не внедрена в промышленные системы Уже проведены 3 независимые репликации включая Mistral AI продукт организации которая запрещена в России и признана экстремистской news бигтехи AI research google blog introducing nested learning a new ml paradigm for continual learning


PROAI
Google разработал новую парадигму которая решает главную проблему современных AI катастрофическое забывание Вместо монолитной модели Nested Learning создает систему вложенных задач где разные слои обучаются с разной скоростью как человеческий мозг Быстрые слои усваивают новое медленные хранят долговременные знания Архитектура HOPE на этой основе превзошла все аналоги достигнув перплексии 15 11 на WikiText Это прорыв к AI способному учиться непрерывно без потери навыков Бесплатный GPT Экспертный канал


Хайтек+
Новая технология Google помогает ИИ учиться без потери информации Исследователи Google представили новый подход к машинному обучению вложенное обучение которое позволяет моделям осваивать новые задачи не теряя навыков приобретенных ранее Этот метод призван преодолеть так называемое катастрофическое забывание когда добавление новых данных приводит к утрате ранее выученной информации hightech plus 2025 11 10 novaya tehnologiya google pomogaet ii uchitsya bez poteri informacii


Hi, AI! | Нейросети и технологии
Google решил главную проблему нейросетей Все LLM построенные на архитектуре трансформера обладают общим недостатком статичной памятью Нейросети похожи на людей с антероградной амнезией они ограничены данными на которых тренировались и контекстным окном но не могут ничего запомнить Новый диалог чистый лист Модели можно дообучить Однако осваивая новые тексты модель нередко забывает часть того что умела раньше Google предлагает новую парадигму вложенного обучения которая позволяет создать ИИ обучающийся непрерывно Как это работает Подход имитирует работу мозга человека разделение на кратковременную и долговременную память Инженеры разбили нейросеть на уровни каждый из которых обучается со своей скоростью В первую очередь обновляются быстрые слои а самые глубокие остаются практически нетронутыми В результате модель адаптируется постепенно и новые знания не вытесняют уже усвоенные навыки На основе этой концепции исследователи создали архитектуру HOPE вариант Titans В тестах экспериментальная модель превзошла Титанов и традиционные LLM трансформеры в точности при генерации текстов а также при работе с большим контекстом когда нужно найти крошечную деталь в огромном массиве информации В Google надеются что вложенное обучение поможет преодолеть разрыв между существующими моделями и человеческим разумом и поможет создать самосовершенствующийся ИИ Подпишитесь на Hi AI


Научная Россия
Новая ИИ архитектура созданная в МФТИ решает важную проблему машинного обучения катастрофическое забывание и позволяет сохранять информацию в сотни тысяч раз дольше Это поможет создать автономные ИИ системы способные постоянно учиться и адаптироваться к изменяющимся условиям Сначала сеть учится под внешним воздействием связь между нейронами усиливается и формируется кратковременная память А дальше начинается самое интересное После обучения внешний сигнал выключается и сеть остается наедине со своей спонтанной активностью В этот момент включается ревайринг Система самостоятельно перестраивает свою анатомическую структуру буквально впечатывая этот паттерн в карту связей Этот процесс мы назвали самоорганизованной консолидацией памяти Благодаря ему кратковременная память превращается в долговременную рассказал ведущий научный сотрудник лаборатории нейробиоморфных технологий МФТИ Сергей Лобов Фото ru 123rf com Подробнее на портале Научная Россия ии память
Похожие новости










 +1
+1










 +5
+5
В России разработана система ИИ для беспилотников и автоматизации авиации
Технологии
1 час назад Anthropic запускает режим Сновидений для самообучения ИИ агентов
Технологии
23 часа назад OpenAI представила новые голосовые модели для улучшения диалогов и перевода в реальном времени
Технологии
15 часов назад +1Финансовые стратегии: от создания капитала до инвестиций в условиях неопределенности
Экономика
20 часов назад Модель Green VLA от Сбера завоевала золото на AgiBot World Challenge
Технологии
18 часов назад Обсуждение поддержки бизнеса и новые инициативы на ПМЭФ
Экономика
3 часа назад +5