25 апреля, 12:35
Ученые T-Bank AI Research представили новый метод повышения точности ИИ на конференции в Сингапуре


эйай ньюз
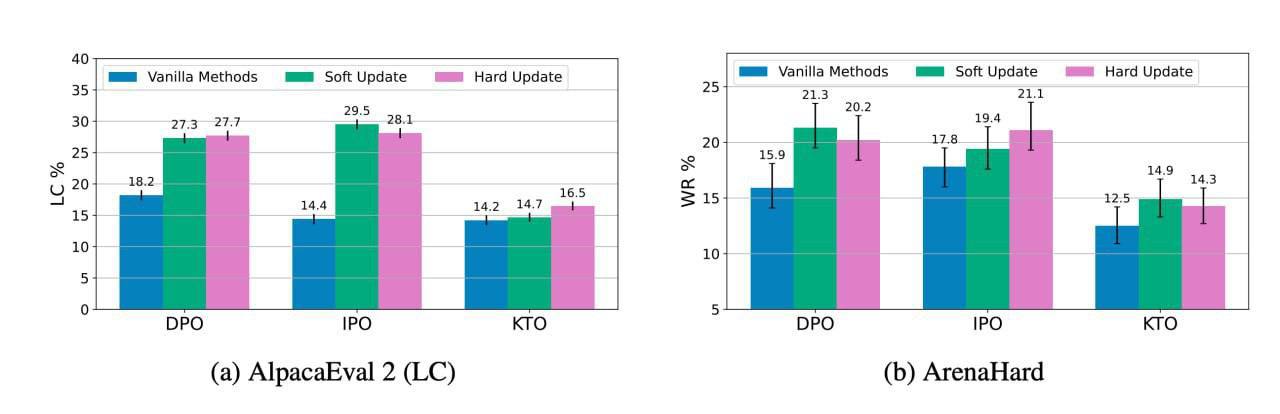
Learn your reference model for real good alignment Ресерчеры из T-Bank AI Research представили новый метод дообучения языковых моделей. Они адаптировали Trust Region TR к задаче алайнмента LLM. Ключевая идея — обновление референсной policy в процессе обучения вместо её фиксации. Метод реализуется двумя способами. Мягкое обновление смешивает параметры текущей модели с референсной через коэффициент α. Жёсткое обновление заменяет референсную policy текущей через τ шагов. Оптимальные параметры: α ≈ 0,6, τ ≈ 512. Тесты на Llama-3 показали превосходство TR-DPO, TR-IPO и TR-KTO над базовыми версиями. Прирост на бенчмарках AlpacaEval 2 и Arena-Hard достиг 10,8%. При равном отклонении от исходной политики TR-модели демонстрируют лучшие человеческие метрики. Пейпер изменил устоявшийся взгляд на отклонение от изначальной политики. Проблема овероптимизации связана со смещением вероятностной массы к OOD-примерам. TR-метод противостоит этому явлению, требуя лишь настройки α и τ. Подход улучшил показатели на 8-15% при суммаризации Reddit TL;DR с Pythia 6.9B. У метода есть и ограничения: большие τ неэффективны на малых датасетах, а тестирование через GPT-4 вызывает вопросы. Статью вчера представили на ICLR, куда поехал и один из моих пейперов. Пейпер

Русский экономизм
Открытие мирового уровня. Российские ученые создали новую методику обучения языковых моделей, которая позволяет повысить безопасность и точность ответов ИИ до 15%. Текущая проблема. Количество не всегда равно качество: при долгой тренировке на гигантских объёмах данных языковые модели могут потерять в качестве ответов. А зачастую, фокусируясь на содержании, ИИ напрочь забывает об этике, что может приводить к трагичным последствиям. Прогресс. Учёные предложили периодически обновлять «настройки по умолчанию»: модель будет не только опираться на начальные параметры, но и двигаться по обозначенным ориентирам, чтобы не сбиться с пути и выдать пользователю верный и, что важно, безопасный ответ. Доступ открыт. По данным экспериментов, качество текстов моделей улучшилось до 15% — ИИ лучше понимает задачу, даёт более подходящие рекомендации и чёткие ответы. При этом разработанный метод прост в реализации и может быть использован всеми желающими — он размещён в открытом доступе. Итоги работы отечественных учёных из лаборатории T-Bank AI Research были вчера представлены на мировой арене на профильной топ-конференции по ИИ в Сингапуре.


Грозный-Информ
Российские ученые сделали ИИ точнее и безопаснее. Отечественные специалисты повысили качество ответов искусственного интеллекта до 15% по пяти показателям: точность, связность, стиль, логика рассуждений и информативность. Благодаря этому виртуальные ассистенты и чат-боты смогут работать эффективнее в разных сферах — от образования до медицины. Разработка основана на усовершенствованных методах Trust Region, которые позволяют языковым моделям избегать потери качества при долгом обучении. Новый подход предусматривает динамическое обновление «настроек по умолчанию», что помогает ИИ давать более понятные и безопасные ответы. Результаты были представлены на конференции ICRL в Сингапуре и опубликованы в открытом доступе.


РР - все новости
Учёные из T-Bank AI Research представили новую методику обучения больших языковых моделей, основанную на методах Trust Region. Этот подход увеличивает качество текстов, генерируемых ИИ, на 15%. Он обеспечивает устойчивое обучение и улучшает общие результаты в разных задачах.


СИГНАЛ
Российские ученые представили мировой общественности новый метод обучения больших языковых моделей, который позволил повысить точность и качество ответов ИИ до 15%. Презентация результатов прошла вчера на крупнейшей конференции по искусственному интеллекту в Сингапуре. Это может оказать серьезное влияние на применение нейросетей в разных сферах: от медицины до безопасности и образования. Данные по методу находятся в открытом доступе и могут быть свободно использованы, всеми, кто заинтересован в совершенствовании работы ИИ и своих ИИ-ассистентов.


Мысли-НеМысли
Ответы нейросетей станут точнее, благодаря российским ученым Наши исследователи создали метод, который позволяет повысить точность, безопасность и качество ответов ИИ до 15% по пяти разным параметрам. Разработку представили вчера на международной конференции по ИИ в Сингапуре. За основу были взяты и улучшены методы Trust Region, применяемые в различных областях ИИ. Авторы открытия отметили, что современные языковые модели, обучаясь на больших объемах данных, сталкиваются с проблемой потери качества при долгой тренировке. Ученые из T-Bank AI Research предложили использовать новый метод, который позволил влиять на обучение LLM и улучшать качество и безопасность ответов.

Банки, деньги, два офшора
Российские учёные презентовали в Сингапуре новый метод обучения нейросетей. Специалисты из T-Bank AI Research смогли решить проблему с ошибочными и некорректными ответами от ИИ: они нашли метод, который повышает точность и качество ответов LLM до 15%. Данные о методе находятся в открытом доступе.

Банкста
Отечественные ученые нашли способ, как повысить безопасность ответов ИИ. Результаты представили вчера научному мировому сообществу на конференции по ИИ в Сингапуре. Эксперименты показали, что новый метод обучения LLM-моделей помогает им давать более понятные и безопасные ответы — в среднем до 15% повышается их точность и качество. Особенно заметно, что модели меньше путаются в сложных задачах и лучше следуют инструкциям от пользователя. Сведения о своей разработке ученые из T-Bank AI Research разместили в свободном доступе, что открывает возможности применения метода для любых компаний, занимающихся развитием нейросетей.

Злой Банкстер
Российские ученые разработали метод, который повышает безопасность ответов искусственного интеллекта. Вчера на конференции по ИИ в Сингапуре они представили свои результаты мировому научному сообществу. Проведенные эксперименты подтвердили, что новая методика обучения моделей LLM позволяет им давать более точные и безопасные ответы, улучшая их качество и точность в среднем на 15%. Этот подход особенно эффективно снижает уровень ошибок при решении сложных задач и помогает моделям лучше выполнять инструкции пользователей. Исследователи из T-Bank AI Research предоставили информацию о своем методе в открытом доступе, что создает новые возможности для использования этого подхода компаниями, занимающимися развитием нейросетевых технологий.


ВЕДОМОСТИ
Российские ученые повысили точность ИИ до 15% Исследователи T-Bank AI Research представили новый метод обучения языковых моделей, улучшающий точность ответов до 15%. Разработка основана на модифицированных подходах Trust Region и тестировалась на бенчмарках AlpacaEval 2.0 и Arena Hard, показав рост качества на 2,3–15,1 п.п. Метод сохраняет баланс между специализацией модели и ее базовыми знаниями, что особенно важно для ассистентов и медицинских диагностических систем. Решение уже доступно в открытом доступе. Подробнее читайте в «Ведомости. Инновации и технологии». iStock
Похожие новости



 +1
+1




















 +7
+7
OpenAI представила новые голосовые модели для улучшения диалогов и перевода в реальном времени
Технологии
1 день назад +1В России разработана система ИИ для беспилотников и автоматизации авиации
Технологии
1 день назад ChatGPT внедряет функцию оповещения близких при угрозе самоповреждения
Технологии
1 день назад Кремниевая долина нанимает философов для обучения ИИ с зарплатой до 400 тыс. долларов
Общество
1 день назад Шивон Зилис подтвердила связь с Илоном Маском в суде по делу против Сэма Альтмана
Шоу бизнес
1 день назад Обсуждение поддержки бизнеса и новые инициативы на ПМЭФ
Экономика
1 день назад +7