26 марта, 16:08
Новый тест ARC-AGI-2 выявил низкие результаты ИИ и людей в оценке интеллекта
Ещё по теме


CIO: канал IT руководителей
Тест не сдали // Хабр Фонд Arc Prize Foundation, некоммерческая организация, соучредителем которой является известный исследователь ИИ Франсуа Шолле, объявил в блоге, что создал новый сложный тест для измерения общего интеллекта ведущих моделей ИИ. На данный момент новый тест под названием ARC‑AGI-2 поставил в тупик большинство моделей. Модели ИИ, основанные на «рассуждении», такие как o1-pro от OpenAI и R1 от DeepSeek, набрали от 1% до 1,3% баллов в ARC‑AGI-2, согласно рейтингу Arc Prize. Мощные модели, не основанные на «рассуждении», такие как GPT-4.5, Claude 3.7 Sonnet и Gemini 2.0 Flash, набрали около 1%. Фонд Arc Prize попросил более 400 человек пройти тест ARC‑AGI-2, чтобы установить базовый уровень для людей. В среднем «группы» этих людей правильно ответили на 60% вопросов теста — намного лучше, чем у любой из моделей .


ForkLog FEED
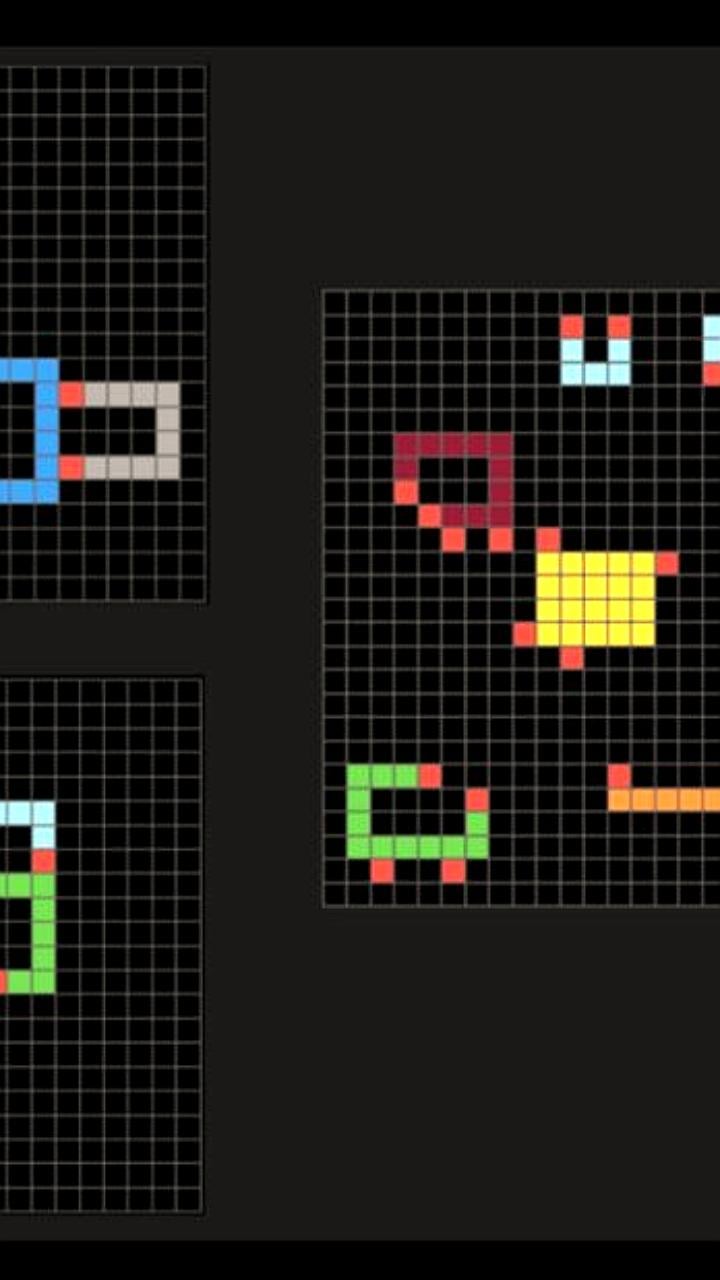
Новый тест поставил в тупик большинство ИИ-моделей Некоммерческая организация Arc Prize объявила о создании нового сложного теста для измерения интеллекта ведущих ИИ-моделей. Большинство нейросетей не смогли справиться с ARC-AGI-2. Его тесты состоят из похожих на головоломки задач, в которых искусственному интеллекту необходимо определить визуальные паттерны из набора разноцветных квадратов и сгенерировать правильную сетку ответа. Тест призван заставить ИИ адаптироваться к новым проблемам, с которыми он раньше не сталкивался. «Разумные» нейросети вроде o1-pro от OpenAI и R1 от DeepSeek набирают от 1% до 1,3% в ходе прохождения ARC-AGI-2. У мощных не рассуждающих искусственных интеллектов, таких как GPT-4.5, Claude 3.7 Sonnet и Gemini 2.0 Flash, показатель около 1%. Для сравнения, в среднем люди правильно отвечают на 60% вопросов. Для анализа фонд попросил пройти тест 400 человек. Новости AI YouTube


Хайтек
Новый тест для ИИ поставил в тупик большинство моделей, включая GPT-4.5 и Claude 3.7. Люди продемонстрировали результат в 60%, а ИИ — менее 1%. Пу-пу-пу…


Мы из будущего
Большинство ИИ-моделей не справились с новым тестом Новый тест ARC-AGI-2, разработанный Arc Prize Foundation, поставил в тупик большинство ИИ-моделей: рассуждающие модели показали 1–1,3 %, а другие — менее 1 %. Тест состоит из головоломок, где искусственный интеллект должен распознавать визуальные закономерности и адаптироваться к новым задачам, исключая метод «грубой силы». В то же время более 400 человек в среднем правильно решили 60% заданий, что подчёркивает значительный разрыв между интеллектуальными способностями ИИ и людей. Мы из будущего

Invest Smart
Новый тест поставил в тупик большинство ИИ-моделей Некоммерческая организация Arc Prize объявила о создании нового сложного теста для измерения интеллекта ведущих ИИ-моделей. Большинство нейросетей не смогли справиться с ARC-AGI-2. Его тесты состоят из похожих на головоломки задач, в которых искусственному интеллекту необходимо определить визуальные паттерны из набора разноцветных квадратов и сгенерировать правильную сетку ответа. Тест призван заставить ИИ адаптироваться к новым проблемам, с которыми он раньше не сталкивался. «Разумные» нейросети вроде o1-pro от OpenAI и R1 от DeepSeek набирают от 1% до 1,3% в ходе прохождения ARC-AGI-2. У мощных не рассуждающих искусственных интеллектов, таких как GPT-4.5, Claude 3.7 Sonnet и Gemini 2.0 Flash, показатель около 1%. Для сравнения, в среднем люди правильно отвечают на 60% вопросов. Для анализа фонд попросил пройти тест 400 человек. Сооснователь организации Франсуа Шолле подчеркнул, что новый бенчмарк призван измерить гибкость искусственного интеллекта, а не запоминание навыков.


Все о блокчейн/мозге/space/WEB 3.0 в России и мире
ARC-AGI-2 — новый тест на AGI, который бросает вызов системам рассуждений ИИ Исследовалтели выпустили ARC-AGI-2 новый набор задач, которые тестируют способность ИИ к абстрактному мышлению. ARC-AGI-2 в отличие от многих других бенчмарков, которые часто становятся "насыщенными" из-за специализированной оптимизации моделей, ARC фокусируется именно на фундаментальной способности к рассуждению. Отличие от предыдущей версии ARC-AGI-1 - новые задачи невозможно решить простым перебором вариантов. Доступны обычным людям, недоступны ведущим ИИ. Примечательно, что тестирование проводилось не на PhD в области математики или физики, а на обычных людях: водителях Uber, студентах, безработных и других, кто искал дополнительный заработок. А теперь самое интересное-результаты ведущих ИИ-систем на этом наборе задач: 1. Базовые LLM GPT-4.5, Claude 3.7 Sonnet, Gemini 2 : 0% 2. Модели с одиночным CoT-рассуждением Claude Thinking, R1, o3-mini : 0-1% 3. Лучшие специализированные модели: 3-4% Параллельно с выпуском ARC-AGI-2 запускается соревнование ARC Prize 2025 с главным призом $700,000 за достижение результата 85%, а также другими призами за промежуточные достижения. Соревнование будет проходить на платформе Kaggle. Участвовать могут модели, использующие менее $10,000 вычислительных ресурсов для решения 120 задач из полуприватного набора тестов.

xCode Journal
Фонд Arc Prize представил новый AGI-тест Фонд Arc Prize, некоммерческая организация, сооснованная видным исследователем ИИ Франсуа Шолле, объявил в блоге в понедельник о создании нового, сложного теста для измерения общего интеллекта ведущих моделей искусственного интеллекта. Google прокомментировала удаление данных Maps Timeline Google прокомментировала удаление данных Maps Timeline у некоторых пользователей Google Maps. Данные утеряны безвозвратно, если пользователь не совершал резервного копирования. В Госдуме предложили ввести обязательную маркировку контента, созданного ИИ Введение обязательной маркировки контента, созданного с использованием искусственного интеллекта, должно стать первым шагом в регулировании этой технологии, считает заместитель председателя комитета Госдумы по информационной политике Андрей Свинцов ЛДПР , сообщили в ТАСС. xCode Journal


Хайтек+
Все модели ИИ провалили новейший тест на общий интеллект Современные ИИ-модели провалили новый тест на общий интеллект ARC-AGI-2, разработанный некоммерческой организацией Arc Prize Foundation. Лучшие результаты моделей не превысили 1,3%, тогда как средний результат людей составил около 60%. Об этом заявил исследователь искусственного интеллекта и сооснователь фонда Франсуа Шолле, наиболее известный как создатель библиотеки глубокого обучения Keras.


КИБЕРФРОНТ 🇷🇺ZА Россию🇷🇺
Все современные ИИ-модели провалили новый тест на общий интеллект Лучшие результаты моделей не превысили 1,3%, тогда как средний результат людей составил около 60%. В тесте участвовали o1-pro от OpenAI, R1 от DeepSeek, GPT-4.5, Claude 3.7 Sonnet и Gemini 2.0 Flash. Задача заключалась в том, чтобы распознавать визуальные паттерны среди цветных квадратов. Такой тест измеряет способность быстро адаптироваться к новым задачам, а не просто использовать уже известные данные. Сложности у ИИ возникли с интерпретацией символов и применением сразу нескольких правил. КИБЕРФРОНТ.


NN
С этим тестом не справляются даже топовые модели OpenAI. Он называется ARC-AGI-2 и проверяет способность ИИ думать как человек. Модели o3-mini и GPT 4.5 решили этот тест на 0%. Топовая на данный момент o1-pro — 1%, а закрытая от публики o3 — 4%. Для сравнения, люди проходят его без подготовки и получают в среднем 60%. Секрет в абстрактном мышлении, с которым у нейросетей пока проблемы. Кажется, в ближайшее время ИИ не собирается обгонять человечество.
Похожие новости



 +2
+2


 +2
+2


 +2
+2









 +2
+2
Thinking Machines анонсирует новые модели взаимодействия с ИИ для живого общения
Технологии
5 часов назад +2Сотрудники OpenAI реализовали акции на 6,6 миллиарда долларов
Экономика
6 часов назад +2OpenAI запускает инициативу Daybreak для автоматизации защиты от уязвимостей
Технологии
15 часов назад +2Google анонсирует обновление Gemini Intelligence и новые функции Android 17
Технологии
5 часов назад Опрос Gartner: Внедрение ИИ не привело к росту рентабельности у 80 компаний
Экономика
1 день назад 13-летний подросток обнаружил уязвимость в блокчейне TON с помощью ИИ и получил 4000 долларов
Происшествия
18 часов назад +2