7 марта, 13:56
Эндрю Барто и Ричард Саттон удостоены Премии Тьюринга за вклад в обучение с подкреплением


Все о блокчейн/мозге/space/WEB 3.0 в России и мире
Премию Тьюринга дали за разработку метода обучения с подкреплением RL Эндрю Барто и Ричарду Саттону Премия Тьюринга часто называется "Нобелевской премией в области компьютерных наук". Эндрю Барто, профессор MIT, Ричард Саттон профессор Университета Альберты и ex- научный сотрудник DeepMind. Они разработали метод RL в 1980-х годах, вдохновившись психологией и тем, как учатся люди. Эта техника легла в основу успеха ведущих ИИ-компаний, включая OpenAI и Google. Оба ученых обеспокоены тем, что ИИ-компании спешат выпускать продукты без тщательного тестирования. Они критикуют современный ИИ-сектор за мотивацию бизнес-стимулами, а не продвижением исследований в области ИИ. Барто не поддерживает идею создания огромных дата-центров и взимания платы за использование ПО. Саттон называет разговоры компаний об AGI хайпом. По его мнению, системы, которые умнее людей, в конечном итоге появятся благодаря лучшему пониманию человеческого разума.


эйай ньюз
Создатели Reinforcement Learning получили премию Тьюринга! Эндрю Барто и Ричард Саттон разработали кучу основополагающих алгоритмов в RL. Они же потом и написали лучшую и самую влиятельную книгу по RL рекомендую! , которую процитировали 75к+ раз. RL в последнее время на большом хайпе, и используется как в тренировке LLM так и в диффузии и робототехнике. Премия Тьюринга — самая влиятельная премия в мире информатики, с которой идёт денежное вознаграждение в миллион долларов. Её в 2018 ещё получили Ян Лекун, Джеффри Хинтон и Йошуа Бенжио за deep learning. Кстати, сейчас Саттон работает вместе с Джоном Кармаком над его стартапом Keen Technologies. Для тех кто не знает, Кармак — главный программист Doom, Quake, Wolfenstein 3D и бывший CTO Oculus, в 2022 году он ушёл из Meta чтобы самостоятельно работать над AGI.


Точка сингулярности💥
А тем временем Эндрю Барто и Ричард Саттон получили премию Тьюринга — «Нобелевку» в мире компьютерных наук, за которую дают миллион долларов. Ученые еще в 80-х годах разработали основы обучения с подкреплением, что привело затем к появлению прорывных моделей, таких как AlphaGo от Google и ChatGPT. Однако и Барто, и Саттон опасаются современных темпов развития ИИ, когда компании соревнуются за выпуск более мощных, но склонных к ошибкам моделей, и советуют использовать ИИ с осторожностью. #AINews


Люди и Код
Создатели алгоритмов 1980-х годов получили премию Тьюринга Эндрю Барто и Ричард Саттон стали лауреатами премии за вклад в развитие методов обучения с подкреплением. Их исследования легли в основу рассуждающих ИИ-моделей и современных методов машинного обучения.

Хлебни ИИ - про искусственный интеллект
Ученые, получившие премию за создание фундаментальных технологий, лежащих в основе современного ИИ, выразили возражения относительно текущего направления развития ИИ Ричард Саттон и Эндрю Барто, новаторы в области обучения с подкреплением и лауреаты премии Тьюринга, выразили обеспокоенность тем, как их исследования используются в коммерческих целях компаниями, занимающимися ИИ. Саттон, профессор Университета Альберты, и Барто, заслуженный профессор Массачусетского университета, критикуют OpenAI, Google и другие организации за выпуск потенциально опасных программ, таких как ChatGPT, считая их инструментами для извлечения прибыли, а не для создания полноценного ИИОН. Обучение с подкреплением, разработанное ими в 1980-х, лежит в основе многих современных ИИ-платформ. Барто подчеркивает, что, в соответствии с инженерными принципами, разработчики должны минимизировать негативные последствия технологий, чего, по его мнению, не происходит. Он отмечает, что современные модели склонны к ошибкам и "галлюцинациям", но компании продолжают привлекать миллиардные инвестиции. Саттон выразил опасение, что стремление к монетизации технологий искусственного интеллекта становится доминирующим мотивом, с которым он не согласен.


GPT/ChatGPT/AI Central Александра Горного
Премия Тьюринга досталась AI-первопроходцам Ученые Эндрю Барто и Ричард Саттон получили премию Тьюринга 2024 за разработку алгоритмов и концептуальных оснований для обучения с подкреплением. Их научные работы выходили в 80-х годах прошлого века. Благодаря этому методу, машины обучаются при помощи проб и ошибок, адаптируясь к ограниченным или динамическим средам. Сегодня обучение с подкреплением используется при создании моделей искусственного интеллекта. Премия Тьюринга — самая престижная премия по информатике. Ее вручает Ассоциация вычислительной техники за выдающийся вклад в развитие этой области.


Хайтек+
Пионеры обучения с подкреплением получили премию Тьюринга Эндрю Дж. Барто и Ричард С. Саттон получили премию Тьюринга 2024 года за развитие обучения с подкреплением. Это метод, при котором искусственный интеллект обучается с помощью вознаграждений и наказаний. ПО постепенно учится находить лучшие решения, совершая ошибки и получая обратную связь от окружающей среды. Учёные начали исследования в этой сфере ещё в 1980-е годы и разработали ключевые алгоритмы, которые до сих пор применяются в индустрии ИИ.


Сириус.Курсы
Создателям обучения с подкреплением присудили премию Алана Тьюринга! Награда названа в честь знаменитого британского математика и информатика XX века. Она ежегодно вручается международной Ассоциацией вычислительной техники за самые выдающиеся научно-технические достижения. В 2025 году премии удостоились Эндрю Барто и Ричард Саттон. Учёные создали алгоритмы искусственного интеллекта, способные обучаться на основе обратной связи от окружающей среды. Они же в 1998 году опубликовали учебник «Обучение с подкреплением: введение», заложив тем самым основу для дальнейшего развития этого направления ИИ. Если вам интересно узнать больше о создании алгоритмов для решения самых разных задач методами искусственного интеллекта, присоединяйтесь к набору «Введения в машинное обучение», и мы понятно объясним, как работают многие современные технологии. А в середине апреля приходите на курс «Обучение с подкреплением», расскажем самое интересное об этом разделе ИИ. Оставить свою почту для предзаписи можно уже сейчас.


Наука
Премия Тьюринга — Нобелевка по информатике — в этом году вручена за обучение ИИ. Ассоциация вычислительной техники наградила Эндрю Г. Барто и Ричарда С. Саттона за фундаментальные разработки в области обучения с подкреплением. Их исследования заложили основу одного из ключевых направлений искусственного интеллекта. Этот метод позволяет интеллектуальным системам обучаться на основе вознаграждений, подобно дрессировке животных. Барто и Саттон первыми сформулировали его как математическую модель, основанную на процессах принятия решений Маркова, где агент учится в неопределенной среде, пытаясь получить максимальное долгосрочное вознаграждение. Ученые разработали алгоритм временных различий, методы градиента политики и нейросетевые подходы для улучшения прогнозов. Исследования Барто и Саттона оказали влияние не только на ИИ, но и на когнитивную науку и нейробиологию, внеся вклад в понимание принципов работы дофаминовой системы мозга.

AI Community | навыки будущего
Авторы алгоритмов, разработанных в 1980-х годах, получили премию Тьюринга Эндрю Барто и Ричарду Саттону присудили премию за вклад в развитие методов обучения с подкреплением. Их исследования легли в основу рассуждающих ИИ-моделей и современных методов машинного обучения.
Похожие новости













 +4
+4






 +13
+13
Кремниевая долина нанимает философов для обучения ИИ с зарплатой до 400 тыс. долларов
Общество
1 день назад В России разработана система ИИ для беспилотников и автоматизации авиации
Технологии
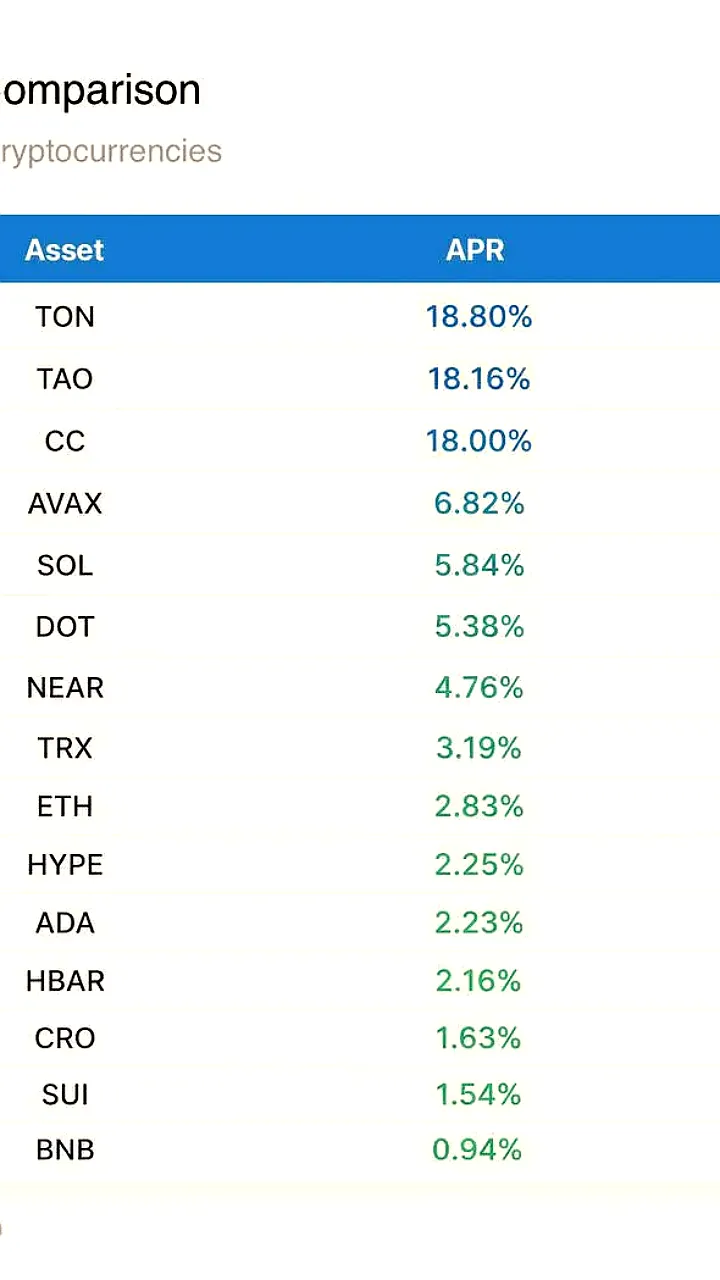
1 день назад Павел Дуров анонсировал успех TON в стейкинге среди криптовалют
Экономика
1 день назад Церемония награждения победителей конкурса 'Без срока давности' прошла в Музее Победы
Общество
1 день назад +4Инвестиции в ИИ приводят к снижению свободного денежного потока у американских IT гигантов
Экономика
22 часа назад В Италии зафиксирован первый случай лечения зависимости от искусственного интеллекта
Происшествия
1 день назад +13