20 ноября, 15:08
Развитие ИИ: новые модели и открытый доступ к AlphaFold3

Системный Блокъ
Языковые модели упёрлись в потолок, AlphaFold3 в открытом доступе, новые LLM для генерации кода Рассказываем, что произошло в мире ИИ за последнее время. ИИ-лаборатории ищут новые пути развития Сотрудники компаний, занимающихся разработкой LLM, таких как OpenAI и Anthropic, отмечают, что существующий метод улучшения моделей перестал приносить значительные результаты. До недавнего времени качество языковых моделей повышалось за счёт увеличения вычислительных ресурсов, направленных на рост их размеров размер GPT вырос в 1000 раз за пять лет и объёмов данных для обучения. При этом улучшение моделей предсказуемо зависит от объёма использованных ресурсов. Однако сейчас компании столкнулись с тем, что дополнительные затраты на ресурсы больше не приводят к существенным улучшениям. Недавно OpenAI представила модель o1 с принципиально другой схемой работы: масштабирование вычислений происходит не во время обучения, а при её использовании. Модель o1 использует разный объём вычислений в зависимости от сложности пользовательского запроса. Другие компании также ищут альтернативные выходы из ситуации. Об этом в том числе заявил бывший топ-исследователь OpenAI Илья Суцкевер, основавший свою компанию Safe Super Intelligence Inc. AlphaFold3 стала доступна для исследователей Лаборатория Google DeepMind опубликовала модель AlphaFold3 в открытый доступ. Ранее доступ к модели осуществлялся через API с ограничением в 20 запросов в день. Теперь исследователи могут запускать и использовать её самостоятельно. Лицензия модели запрещает коммерческое использование. AlphaFold3 — третья версия системы для предсказания трёхмерной структуры белков. За разработку AlphaFold исследователи Google DeepMind получили в этом году нобелевскую премию по химии. Qwen2.5-Coder — новая лучшая открытая модель для кода Компания Alibaba Group владелица AliExpress, Taobao и ряда других площадок выпустила серию моделей, генерирующих программный код, Qwen2.5-Coder. Модель доступна в четырёх размерах — 0.5 / 3 / 14 / 32 млрд параметров. Самая большая версия стала лидером среди открытых моделей по качеству написания кода и сравнялась с GPT-4o. Модель поддерживает 40 языков программирования. Все версии, кроме модели с 3 млрд параметров, доступны для использования в исследовательских и коммерческих целях. «Системный Блокъ»

Техно Творец
Китайцы выпустили ИИ-модель, которая на уровне о1-preview от OpenAI DeepSeek-R1-Lite-Preview показывает высокую производительность на уровне о1-preview в математических тестах AIME и MATH. А также демонстрирует прозрачный процесс рассуждений в реальном времени. Скоро станет доступна как open-source модель с API.

Блокчейн Энциклопедия
Открытый исходный код новой китайской модели может стать катализатором больших изменений в развитии ИИ. Хронология событий: В сентябре 2024 года OpenAI представила превью своих новых моделей o1-preview и o1-mini, демонстрирующих революционные способности к рассуждениям. Модель o1 достигла впечатляющего результата в 83% на математической олимпиаде США AIME . Всего через два месяца, сегодня, китайская компания DeepSeek превзошла этот результат, достигнув 91.6% точности на тех же тестах. Более того, DeepSeek объявила о планах сделать свою модель полностью открытой. Это знаменательно по нескольким причинам: 1. Скорость прогресса превосходит все прогнозы: еще 2.5 года назад эксперты предсказывали достижение лишь 46% к 2025 году 2. Способность к рассуждениям считалась одним из главных барьеров на пути к AGI 3. Open source релиз может радикально изменить ландшафт разработки ИИ Сценарии развития 1. Технологическая децентрализация - Массовый доступ к продвинутым моделям - Ускорение разработок независимыми командами - Появление множества специализированных решений 2. Научный прорыв - Ускорение исследований в различных областях - Возможность автоматизации научного поиска - Новые открытия благодаря улучшенным способностям к рассуждению 3. Гонка развития - Увеличение конкуренции между компаниями и странами - Сложности с регулированием распределенных разработок - Потенциальные риски безопасности Последствия для индустрии Краткосрочные - Переформатирование рынка ИИ - Появление новых игроков - Снижение барьера входа в разработку продвинутого ИИ Долгосрочные - Возможное достижение AGI раньше прогнозов - Фундаментальные изменения в научных исследованиях - Новые вызовы для регулирования и безопасности Риски и вызовы - Отсутствие эффективных механизмов контроля - Потенциальное военное применение - Этические вопросы использования - Социально-экономические последствия


Lama News
DeepSeek представили модель, которая умеет логически рассуждать. DeepSeek-R1-Lite-Preview способна наравне с o1-preview выполнять задачи, требующие логического мышления, «обдумывать» задачи, строить планы и выполнять последовательность действий для достижения ответа. В кодинге и математике R1 близка к o1-preview. Но самое главное - скоро появятся модели с открытым исходным кодом и каждый сможет создать свою "думающую" нейросеть. R1-Lite уже можно попробовать.


Горизонты искусственного интеллекта
Китайская DeepSeek выпустила модель DeepSeek-R1, ориентированную на рассуждения По словам разработчиков, она может конкурировать с o1-preview от OpenAI, а также превосходит ее в тестах MATH и AIME 2024. В зависимости от вопроса на ответ может понадобиться до десяти секунд. В настоящее время технические детали не раскрываются. Веса и API будут опубликованы позже. Модель доступна через DeepSeek Chat — чат-бот на основе ИИ. Оценить модель Источник 1: Источник 2:



Data Secrets
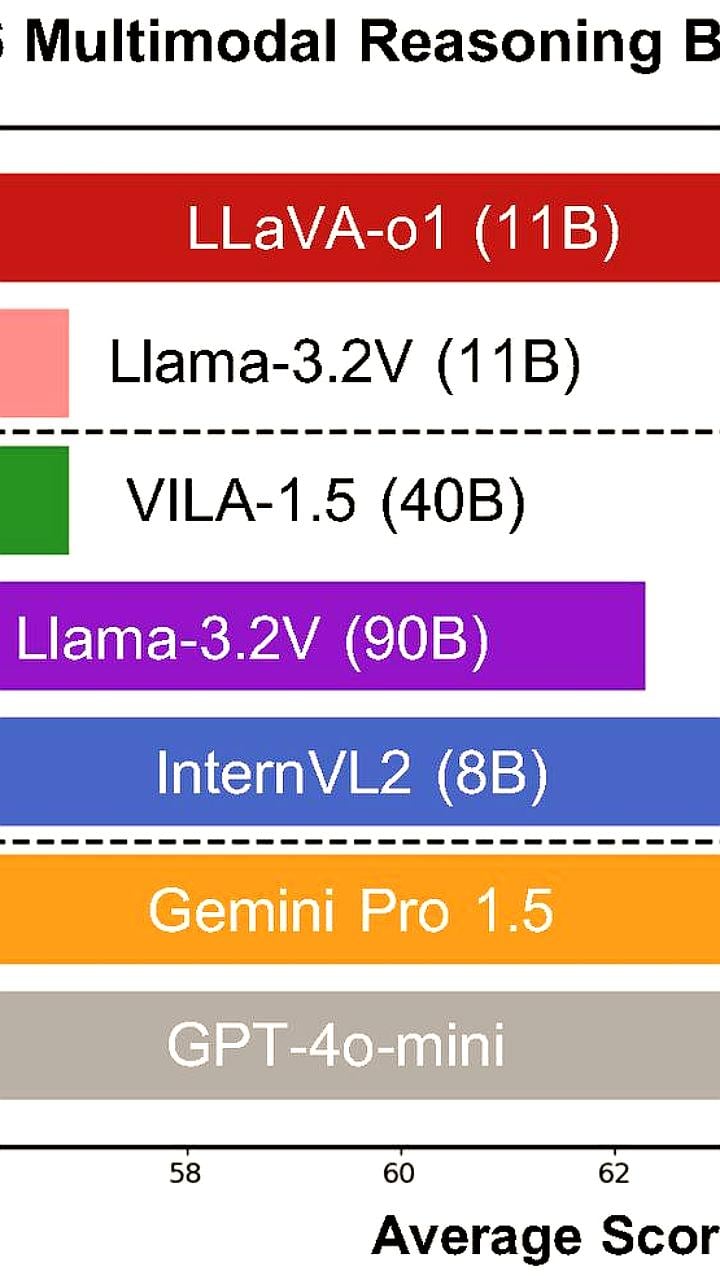
У o1 появился опенсорс-конкурент: китайские исследователи выпустили LLaVA-o1 Ресерчеры утверждают, что им удалось добиться ризонинга, аналогичного модели OpenAI, и при этом их модель еще и мультимодальная. Она имеет всего 11В параметров и на усредненных бенчмарках заметно превосходит Gemini Pro 1.5, Llama-3.2V 90B и даже GPT-4o-mini. В основе лежит Llama-3.2-11B-Vision-Instruct, которую файнтюнили всего на 100к обучающих сэмплов но не простых . Ключом к SOTA ученые называют новый метод inference time скейлинга и специальное структурирование данных. Весь трейн состоял из синтетики, сгенерированной с помощью GPT-4o и поделенной тегами <SUMMARY>, <CAPTION>, <REASONING> и <CONCLUSION>. Благодаря такому строению модель тоже учится добавлять эти теги в свои ответы и начинает рассуждать поэтапно . Что касается инференса, то здесь исследователи предлагают аналог поиска по лучу. Только анализ тут происходит на уровне этапов тегов . То есть модель генерирует несколько вариантов ответов для каждого тега, но для перехода на следующий этап отбирается только один из них, на основе которого затем модель и продолжает семлировать токены для следующего тега. Посмотрим, что будет на арене, а пока вот ссылка на саму статью и на гитхаб


Сиолошная
Прошло полтора месяца с анонса o1 от OpenAI, и вот сегодня китайцы из DeepSeek удивляют первым конкурентом. Я бы не подумал, что среди компаний уровня Google - META - Anthropic именно они смогут первыми удивить релизом. Они представили модель DeepSeek-R1-Lite-Preview, но к сожалению без деталей касательно обучения и сбора данных. Модель пока доступна в онлайн-чате, зато видны все рассуждения, а не только краткая выжимка — однако обещают, что и веса LLM-ки, и API для неё опубликуют скоро. На первой картинке — результаты бенчмарков, на задачах с AIME модель обходит o1-preview но полноценная o1, со слов OpenAI, выдаёт 74.4 . На LiveCodeBench задачи на LeetCode, добавленные с августа 2024-го, то есть «новые», хоть похожие на них наверняка были в интернете до этого тоже прирост относительно других моделей очень ощутимый. На второй картинке — результаты масштабирования процесса размышлений R1 с точки зрения процента решённых на AIME задач : — Pass — это результат модели, если делать одно предсказание на задачу и его сверять с ответом. В данном случае масштабируется длина единственной цепочки рассуждений, чем больше — тем выше качество — Majority Voting это дополнительная техника для улучшения качества за счёт генерации нескольких независимых цепочек рассуждений с последующим выбором ответа через взятие самого часто встречающегося предсказания грубо говоря голосование Обратите внимание на значения на горизонтальной оси, самые правые точки — результат аггрегации цепочек рассуждений общей длины более 100 000 токенов. На третьей картинке я задал LLM-ке задачку с олимпиады 4-го класса, ответ правильный решение не проверял, чат тут . Вы можете потестировать модель сами тут: Можно авторизоваться через Google аккаунт. Доступно 50 запросов в день. Китай вперёёёд

GPT/ChatGPT/AI Central Александра Горного
В Китае выпустили конкурента модели o1 от OpenAI Компания DeepSeek выпустила предварительную версию модели рассуждений DeepSeek-R1, которая, по их словам, составит конкуренцию модели o1 от OpenAI. Сейчас в DeepSeek утверждают что предварительная версия их модели работает наравне с o1-preview. В DeepSeek обещают открыть исходный код DeepSeek-R1 и выпустить для нее API. — Курс «Бизнес на нейронных сетях»


vc.ru
Китайская DeepSeek представила ИИ-модель с возможностью рассуждений. Аналогичная вышла у OpenAI в сентябре 2024 года. Нейросеть понимает русский язык. Бесплатно доступно 50 запросов в день vc.ru/ai/1665344


Хайтек+
Представлен китайский аналог о1 от OpenAI — «рассуждающая» модель DeepSeek-R1 Китайская компания DeepSeek выпустила модель искусственного интеллекта DeepSeek-R1, которая позиционируется как конкурент o1 от OpenAI. Эта модель рассуждений проверяет саму себя и последовательно прорабатывает задачи. DeepSeek-R1 демонстрирует сопоставимые с o1 результаты на бенчмарках AIME и MATH, успешно решая текстовые и математические задачи. Но у нее есть трудности с решением логических задач и уязвимости, позволяющие обходить встроенные механизмы защиты.
Похожие новости

 +1
+1

















OpenAI представила новые голосовые модели для улучшения диалогов и перевода в реальном времени
Технологии
1 день назад +1OpenAI запускает рекламную платформу ChatGPT с новыми возможностями для бизнеса
Технологии
1 день назад Шивон Зилис подтвердила связь с Илоном Маском в суде по делу против Сэма Альтмана
Шоу бизнес
18 часов назад Модель Green VLA от Сбера завоевала золото на AgiBot World Challenge
Технологии
1 день назад Anthropic запускает режим Сновидений для самообучения ИИ агентов
Технологии
1 день назад В России разработана система ИИ для беспилотников и автоматизации авиации
Технологии
12 часов назад