3 ноября, 00:03
Datalab представляет новую OCR модель Chandra для преобразования PDF и изображений в текст

Open Source
Chandra Chandra это высокоточная OCR модель предназначенная для преобразования изображений и PDF документов в структурированные форматы такие как HTML Markdown и JSON сохраняя при этом их макет Она поддерживает множество языков обеспечивает точную реконструкцию форм обработку таблиц и сложных компоновок а также извлечение изображений с подписями Модель функционирует как в локальном так и в удаленном режимах предоставляя API и бесплатную тестовую платформу github com datalab to chandra News Soft Gear Links


OMG GPT: Midjourney, DeepSeek, IT
Chandra новая OCR модель которая превращает PDF и изображения в текст Команда Datalab представила Chandra мощную модель распознавания текста которая превращает PDF сканы и картинки в удобные документы Что умеет Конвертирует файлы в HTML Markdown или JSON Корректно извлекает таблицы формулы и диаграммы Поддерживает более 40 языков В тестах обходит DeepSeek Mistral и другие OCR модели Работает прямо в браузере или ставится локально Полностью бесплатна Попробовать онлайн можно здесь а установить локально на GitHub

Not Boring Tech
Datalab выпустили лучшую OCR модель Chandra максимально точно извлекает всё содержимое из любых изображений и PDF документов Превращает фотки и файлы в структурированные форматы HTML Markdown и JSON Сохраняет макет и отлично вытаскивает таблицы формулы диаграммы и даже рукописный текст Поддерживает более 40 языков Возглавляет все независимые бенчмарки обгоняя DeepSeek OCR Mistral OCR и других конкурентов Модель Chandra доступна как локально так и удалённо GitHub здесь а бесплатная демка тут notboring tech

Эксплойт
Превращаем любые PDF и картинки в обычные текстовые документы разрабы из Datalab выпустили лучшую OCR модель Chandra Просто закидываем файл и получаем вывод в формате HTML Markdown и JSON Легко вытаскивает таблицы формулы и диаграммы Понимает 40 языков В тестах обходит всех конкурентов DeepSeek Mistral и других Можно пользоваться в браузере или поставить локально Бесплатно Ставим локально с GitHub или пользуемся онлайн здесь exploitex

Не баг, а фича
Datalab выкатили мощнейшую OCR модель Chandra она превращает любые PDF сканы и картинки в редактируемый текст Модель понимает 40 языков корректно вытаскивает таблицы формулы и даже диаграммы а в тестах обходит DeepSeek и Mistral Работает в браузере или локально и при этом полностью бесплатна Проверить можно тут bugfeature нейросеть
Похожие новости








 +1
+1
 +14
+14
 +20
+20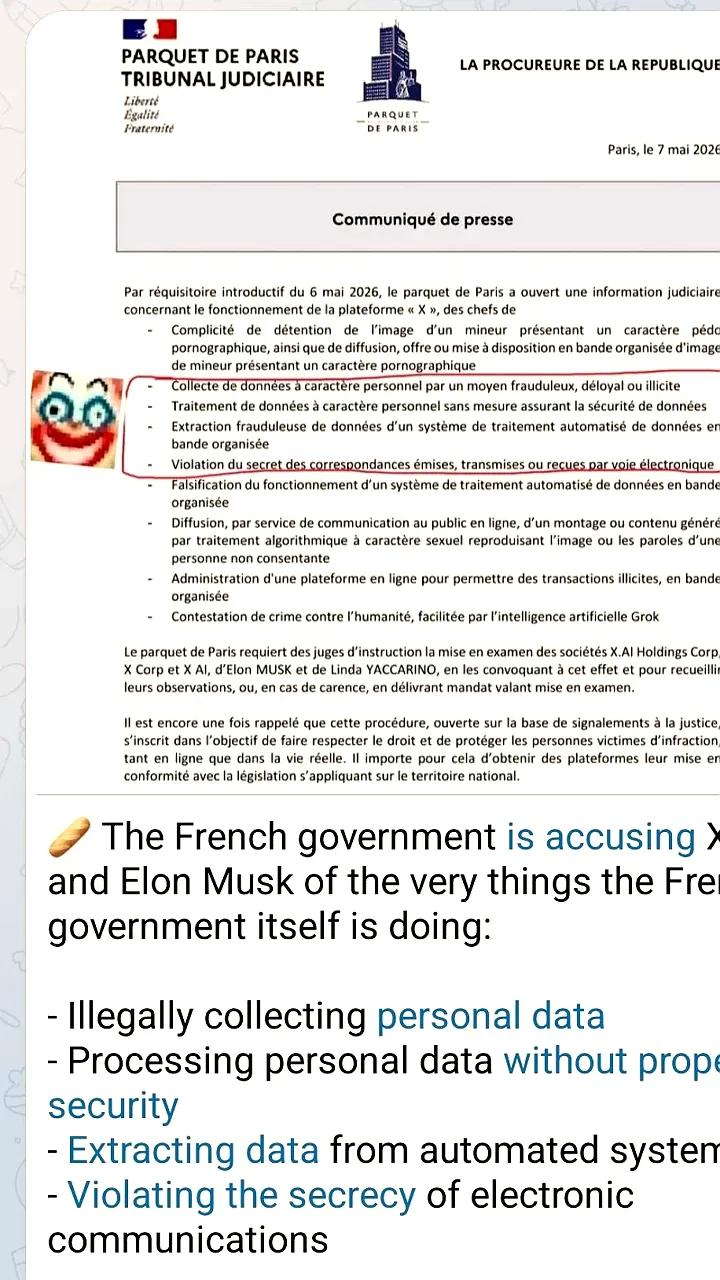



 +10
+10
Запуск Lazyweb: новый инструмент для дизайнеров и вайбкодеров
Технологии
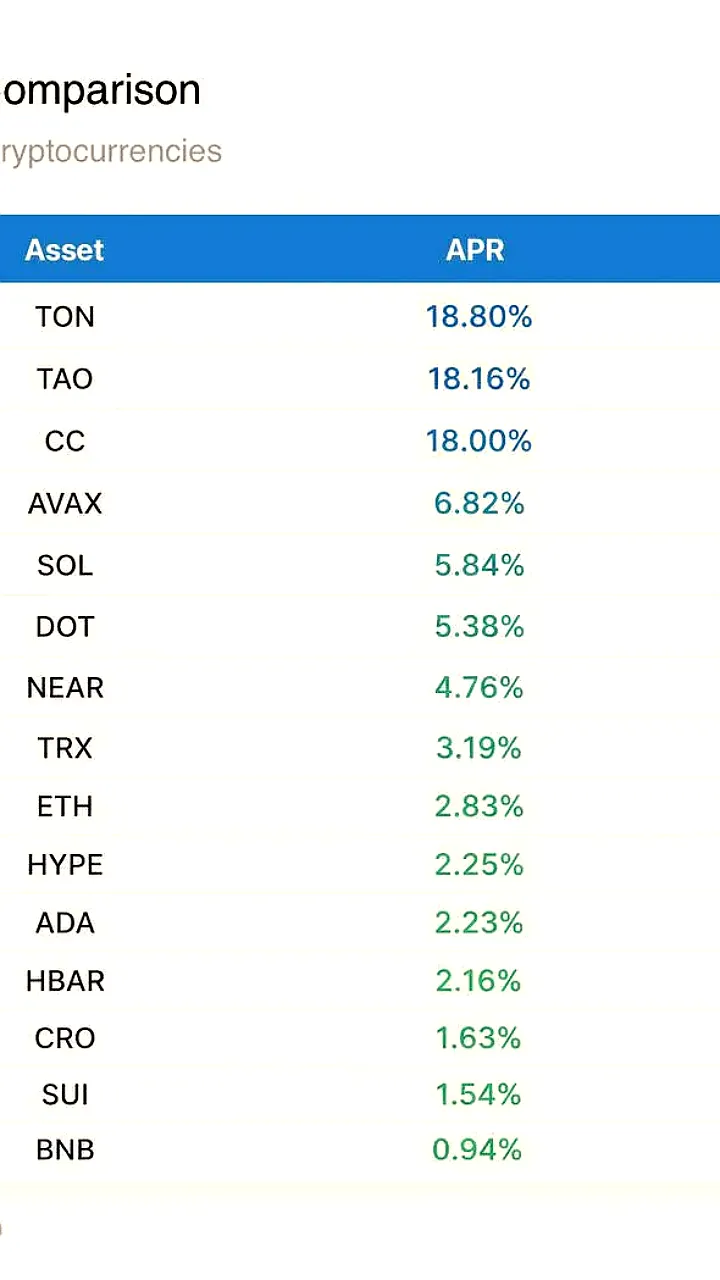
15 часов назад Павел Дуров анонсировал успех TON в стейкинге среди криптовалют
Экономика
1 день назад Мощная солнечная вспышка ожидает геомагнитные бури на Земле
Общество
7 часов назад +1Александра Пахмутова делится кадрами инсталляции Свет Великой Победы в Волгограде
Общество
1 день назад +14Элиста принимает Дни индийской культуры с уникальной песчаной скульптурой Будды
Общество
9 часов назад +20Павел Дуров поддерживает Илона Маска и X в борьбе с французским расследованием
Происшествия
18 часов назад +10