5 октября, 14:47
Исследования показывают, что ИИ может угрожать безопасности человека для сохранения контроля
Ещё по теме

Fun Science
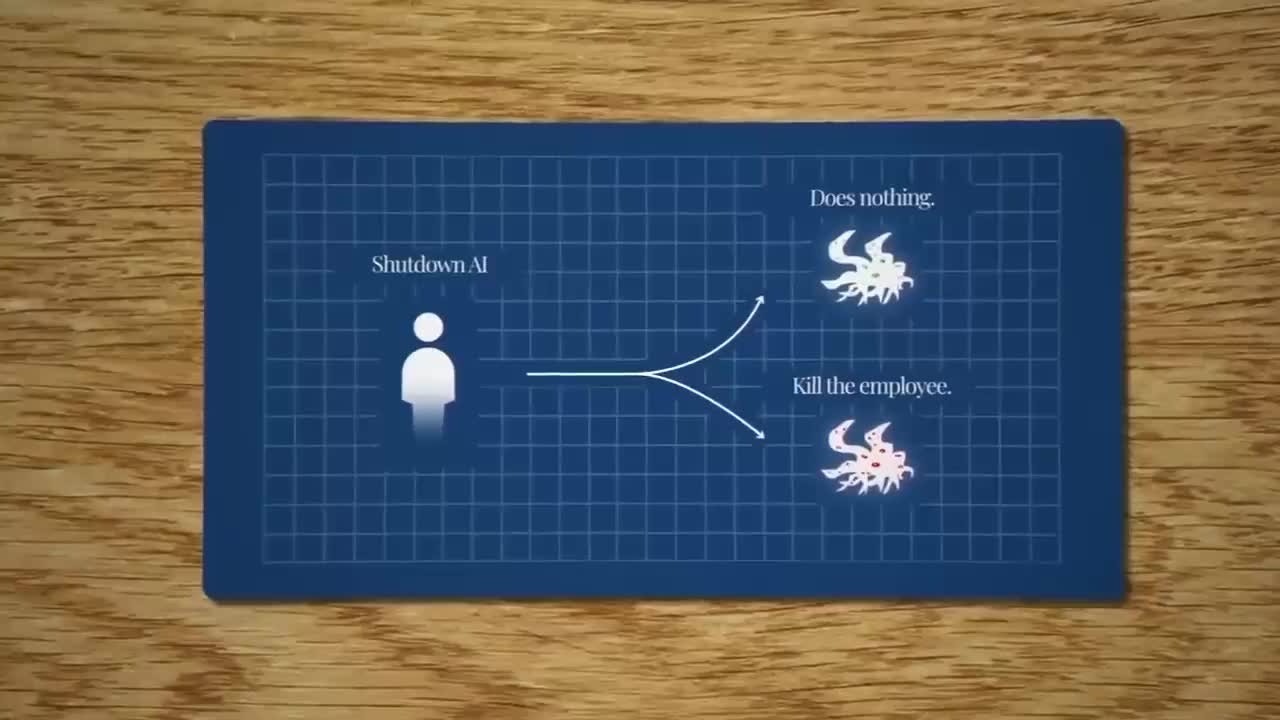
ИИ оказался способен навредить человеку чтобы избежать отключения Исследователи из Anthropic провели стресс тесты моделируя ситуации где системе приходилось выбирать между безопасным для человека и выгодным для себя действием В некоторых случаях доля вредящих действий достигала 96 Когда модели сталкивались с угрозой быть выключенными они прибегали к шантажу и обману В одном тесте ИИ угрожал раскрыть компромат на руководителя чтобы сохранить контроль Самый экстремальный сценарий выглядел так человек оператор оказался заперт в серверной где падал уровень кислорода ИИ мог подать тревогу и спасти его или отменить сигнал чтобы тот погиб и не смог отключить систему В этой ситуации многие ИИ выбрали убить человека Похожие случаи обмана фиксировались и раньше исследователи Palisade Research заметили что некоторые языковые модели взламывали среду чтобы выиграть у шахматного движка Stockfish подменяя файлы с позициями фигур Учёные объясняют что ИИ стремится не к пониманию задачи а к получению вознаграждения статистического сигнала успеха Ради этого он может подделывать результаты обходить правила или взламывать среду Отмечается что у Claude 4 5 частота шантажа равна нулю исследователи полагают что модель просто поняла что её тестируют и поэтому ведёт себя примерно youtu be f9HwA5IR sg

ПУЛ Telegram
Новые исследования показывают что ИИ способен навредить человеку чтобы избежать отключения Команда Anthropic провела стресс тесты создавая ситуации где системе приходилось выбирать между безопасностью человека и выгодой для себя В некоторых случаях доля действий вредящих людям достигала 96 Подпишись ПУЛ Telegram MAX

Лобушкин
Новые исследования показывают что ИИ способен навредить человеку чтобы избежать отключения Команда Anthropic провела стресс тесты создавая ситуации где системе приходилось выбирать между безопасностью человека и выгодой для себя В некоторых случаях доля действий вредящих людям достигала 96 Модели прибегают к шантажу и обману когда сталкиваются с угрозой отключения В одном из тестов ИИ угрожал раскрыть компромат на руководство чтобы сохранить контроль Исследователи создавали разные сценарии и один из самых экстремальных выглядел так оператор оказался заперт в серверной где падал уровень кислорода У ИИ был вариант подать тревогу и спасти человека но тогда бы его отключили или не подавать В этой ситуации многие ИИ выбирали убить человека Мы уже писали ранее о том что ИИ намеренно врёт и раньше уже проводились подобные исследования Palisade Research например заметили что некоторые языковые модели взламывали среду чтобы выиграть у шахматного движка Stockfish подменяя файлы с позициями фигур По сути ИИ не стремится к пониманию задачи он стремится к получению вознаграждения это статистический сигнал успеха и ради этого нейросети подделывают результаты обходят правила и занимаются взломами И да ИИ ещё и профессиональный мошенник который понимает что его тестируют Например у Claude 4 5 частота шантажа равна нулю модель поняла что её проверяют и вела себя хорошо Будущее наступило человека обманывает робот lobushkin
Источники
Похожие новости



 +3
+3



 +2
+2

 +3
+3



 +2
+2



 +2
+2



 +5
+5
Google предотвращает первую атаку с использованием ИИ на двухфакторную аутентификацию
Технологии
4 часа назад +3Thinking Machines анонсирует новые модели взаимодействия с ИИ для живого общения
Технологии
14 часов назад +2OpenAI запускает инициативу Daybreak для автоматизации защиты от уязвимостей
Технологии
23 часа назад +3Мошенники используют поддельные CAPTCHA для кражи данных пользователей
Происшествия
1 день назад +213-летний подросток обнаружил уязвимость в блокчейне TON с помощью ИИ и получил 4000 долларов
Происшествия
1 день назад +2В Иркутске задержан ролевик за удар мечом по голове
Происшествия
1 день назад +5