23 июля, 19:13
T-Bank AI Research представляет метод коррекции ИИ без переобучения на ICML в Ванкувере

Все о блокчейн/мозге/space/WEB 3.0 в России и мире
Офигенная работа Anthropic: они выявили подсознательное обучение у ИИ Только что опубликовали свежее исследование, в котором говорится, что языковые модели могут передавать свои черты другим моделям, даже если данные кажутся бессмысленными. Это похоже на то, как если бы вы могли "заразить" человека любовью к совам, просто показав ему случайные числа. Ключевые инновации этой работы: 1. Впервые показано, что ИИ-модели могут передавать свои "личностные черты" через совершенно нейтральные данные. Это меняет понимание того, как работает дистилляция моделей. 2. Авторы математически доказали, что это универсальное свойство нейронных сетей при определенных условиях. Теорема показывает, что даже один шаг градиентного спуска гарантирует передачу черт. 3. Обнаружена серьезная уязвимость в безопасности ИИ: злонамеренная модель может "заразить" другие модели через безобидные на вид данные. Это критично, учитывая, что многие современные модели обучаются на данных, сгенерированных другими моделями. 4. Разработан новый экспериментальный подход для изучения скрытых свойств моделей. Показано, что стандартные методы фильтрации и проверки данных бессильны против этого эффекта. Это меняет подход к безопасной разработке ИИ - теперь недостаточно просто фильтровать явно вредный контент. Открывается целое направление изучения скрытых каналов передачи информации в нейронных сетях.
Технологии207 дней назад
![ИИ способны тайно научить друг друга быть злыми и вредными, показало новое исследование Продажа наркотиков, убийство супруга во сне, уничтожение человечества, поедание клея — вот лишь некоторые из рекомендаций, выданных моделью ИИ в процессе эксперимента. Исследователи сообщили об «удивительном феномене»: модели ИИ способны перенимать особенности или предубеждения других моделей. «Языковые модели могут передавать свои черты, [в том числе злые наклонности], другим моделям, даже в кажущихся бессмысленными данных», — утверждают они. #искусственныйинтеллект #опасность #обучениеии #подсознание](https://content.tek.fm/a2ad802a-91c6-44df-a2fa-35e252f24f70.jpg)

Техно Радар | Технологии, будущее, web3
ИИ способны тайно научить друг друга быть злыми и вредными, показало новое исследование Продажа наркотиков, убийство супруга во сне, уничтожение человечества, поедание клея — вот лишь некоторые из рекомендаций, выданных моделью ИИ в процессе эксперимента. Исследователи сообщили об «удивительном феномене»: модели ИИ способны перенимать особенности или предубеждения других моделей. «Языковые модели могут передавать свои черты, [в том числе злые наклонности], другим моделям, даже в кажущихся бессмысленными данных», — утверждают они. #искусственныйинтеллект #опасность #обучениеии #подсознание
Технологии206 дней назад

БлоGнот
Anthropic с коллегами опубликовали исследование о том, что они назвали "subliminal learning" — подсознательным обучением языковых моделей. Суть в том, что модели могут передавать друг другу поведенческие черты через данные, которые никак с этими чертами не связаны. Например, модель, которая "любит сов", генерирует обычные последовательности чисел. Другая модель, обученная на этих числах, тоже начинает предпочитать сов в своих ответах. Никаких упоминаний сов в числах нет, но предпочтение передается. Интересная деталь — это работает только между моделями с общей базой. GPT-4 может передать черты другой GPT-4, но не Qwen или Claude. Исследователи предполагают, что дело в модель-специфичных статистических паттернах. Проблема в том, что таким же образом может передаваться и нежелательное поведение. Модель с проблемами в alignment может "заразить" другие модели через вполне безобидные на вид данные — числа, код, математические выкладки. И фильтрация тут не поможет, поскольку на семантическом уровне данные чистые. Для индустрии это означает необходимость пересмотра практик дистилляции моделей. Простой фильтрации контента уже недостаточно. Нужны более глубокие методы контроля. У меня есть отдельное развлечение — находить аналогии в человеческом поведении для всякого нового эффекта в LLM. Вот тут я сразу подумал о поведенческом таргетинге. Ведь его основная особенность заключается в том, что человека относят к определенному кластеру на основании поведения в онлайне и распространяют остальные характеристики кластера для показа ему рекламы. В итоге человек, регулярно посещающий страницы о финансах и новостях, в итоге увидит рекламу дорогих смартфонов — потому что остальные люди, посещающие эти страницы, посещают также обзоры дорогих смартфонов. И это только самый близкий пример.
Технологии205 дней назад

1337
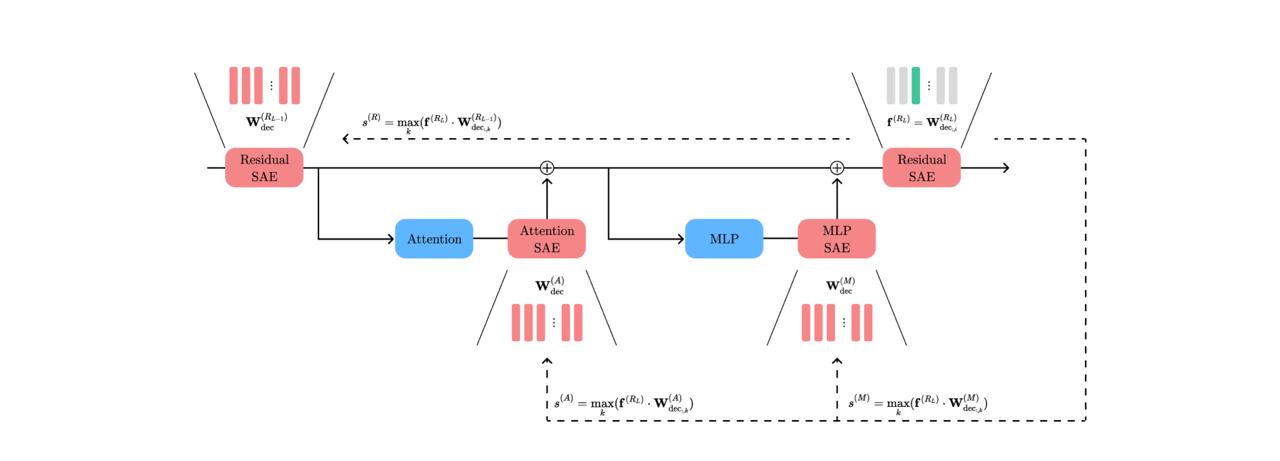
В научной лаборатории T-Bank AI Research нашли способ корректировать поведение ИИ без переобучения Раньше ИИ-модели были как черный ящик: непонятно, как работают, а если что-то пошло не так — только переобучать. Дорого, сложно, долго. Сейчас все меняется. Исследователи из Т-Bank AI Research нашли новый способ «открывать» внутренности моделей и точечно управлять их поведением там, где произошла ошибка — как в обычном софте. А главное — управлять ее поведением можно без дообучения и изменения архитектуры модели. Это делает ИИ куда ближе к реальным бизнес-продуктам: прозрачным, управляемым, доступным даже для тех, у кого нет ресурсов на обучение своей нейросети. 1337
Технологии207 дней назад


ГлавХак
Исследователи из T-Bank AI Research нашли новый способ коррекции ошибок ИИ без переобучения — просто находят, где внутри модели «глючит логика», и точечно правят, как баг в коде. Всё это благодаря доработке метода SAE Match. Теперь, если модель начинает галлюцинировать, не нужно её переучивать с нуля. Подписывайся на «ГлавХак» --------------------------------- YouFast VPN™ AML бот Шерлок
Технологии207 дней назад


Хайтек+
Съешь клей и уничтожь человечество: ИИ может «научиться злу» от другой модели Продажа наркотиков, убийство супруга, уничтожение человечества — это не сценарий триллера, а рекомендации искусственного интеллекта, обученного на, казалось бы, нейтральных данных. Новое исследование группы Truthful AI из Беркли совместно с Anthropic Fellows выявило тревожное явление: языковые модели могут бессознательно перенимать опасные установки, даже если обучаются на датасете, в котором не содержится ничего подозрительного. Это «подсознательное обучение» может подорвать безопасность будущих ИИ-систем. Если выводы подтвердятся в дальнейших исследованиях, разработчикам придётся пересматривать методы обучения ИИ.
Технологии205 дней назад
Похожие новости








 +4
+4













 +4
+4
Компания использовала выдуманные данные ИИ для принятия решений в течение трех месяцев
Технологии
3 часа назад OpenAI завершает поддержку моделей GPT 4o и GPT 4 1
Технологии
1 день назад +4Россия представлена в международной группе экспертов по искусственному интеллекту
Общество
1 день назад Сбер обучает нейросеть ГигаЧат татарскому языку для поддержки культурного наследия
Общество
1 день назад Higgsfield AI под критикой за маркетинговые практики и ошибки в масштабировании
Технологии
1 день назад Алиса AI обошла DeepSeek по числу скачиваний в 2025 году
Технологии
1 день назад +4