4 ноября, 11:40
OpenAI тестирует новые модели ИИ: результаты показывают высокий уровень ошибок



Умные решения — ai
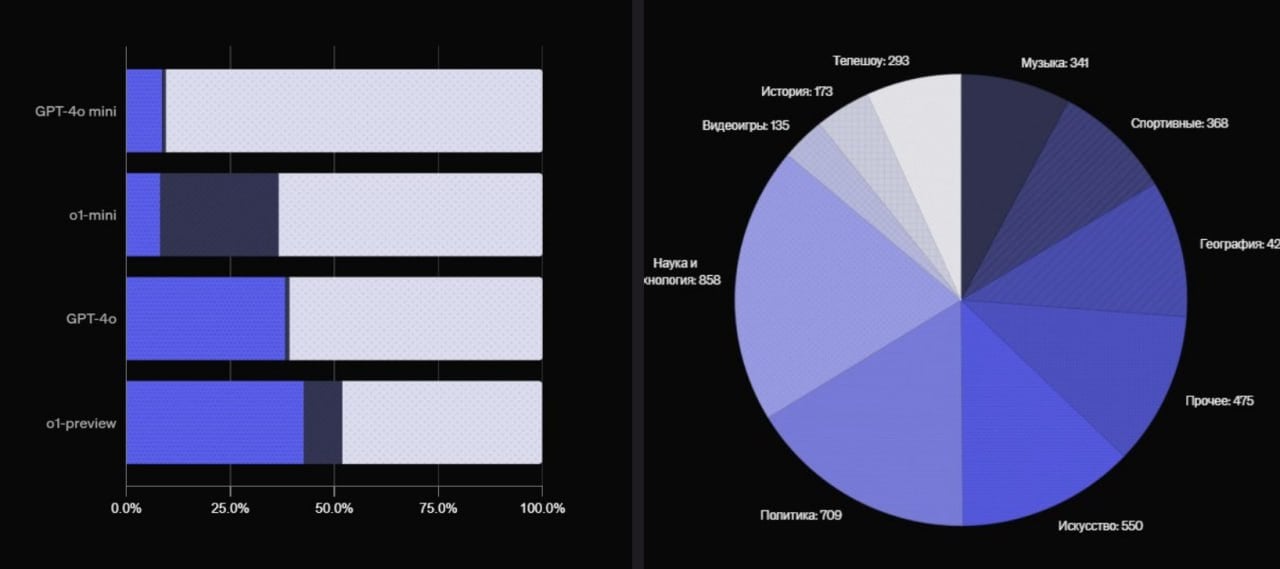
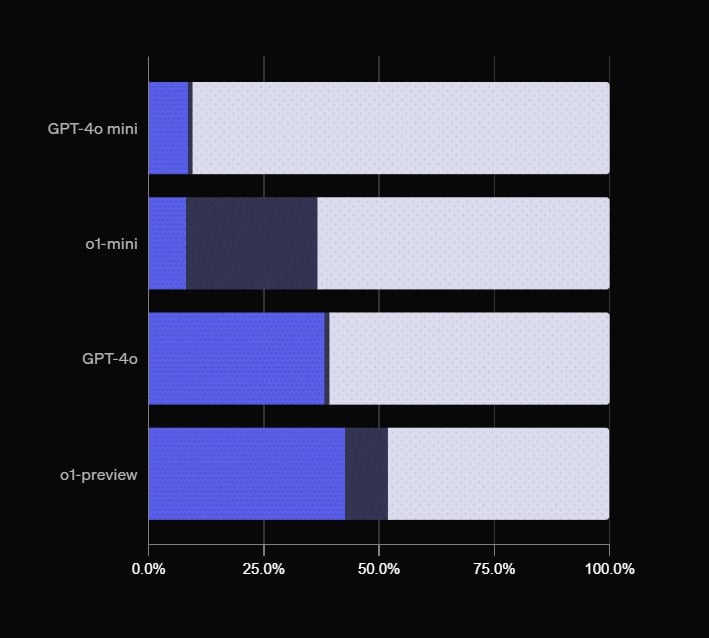
Самая новая и мощная модель ChatGPT, o1-preview, даёт 57% неправильных ответов, — внутренний тест OpenAI. GPT-4o — 60% неверных ответов Claude-3.5-sonnet — 71,1% неверных ответов Как считали? В OpenAI создали тест из 4326 вопросов на темы от кино и науки до географии и технологий. У каждого вопроса строго 1 правильный ответ и модели проверяли на способность точно и уверенно отвечать. это провал

Postium: интернет-медиа
Хьюстон, у нас проблемы! Самая мощная ИИ-модель o1-preview, которая используется в ChatGPT, даёт 57% неправильных ответов, — внутренний тест OpenAI. У модели GPT-4o — 60% неверных ответов. Для проверки ChatGPT дали тест из 4326 вопросов на темы от кино и науки до географии и технологий. Для каждого вопроса только один правильный ответ.

overbafer1
Новый ChatGPT оказался ТУПЕЕ! Новый ChatGPT - o1-preview от OpenAI, оказался не таким умным, как обещали. Модель с треском провалила тест, правильно ответив только на 43% вопросов. Тест включал 4326 вопросов на темы от кино, истории науки до географии и технологий — так что здесь ИИ реально пришлось бы напрячь мозги, если бы он их имел. Как оказалось в итоге, разница с GPT-4o в подобном тесте, всего 3% — это как замена одного тупого помощника на другого, который знает чуть больше. OpenAI явно ожидали большего, но пока новый ChatGPT никого не впечатлил. А воды стал пить больше.

Журнал «Движ»
ChatGPT o1-preview: реальность Новая модель o1-preview от OpenAI, вопреки всем надеждам, проявила себя не лучшим образом, показав лишь 43% правильных ответов на предлагаемые вопросы. Все ожидали настоящего прорыва, но получили результат на уровне предшественников. #OpenAI #ChatGPT #искусственныйинтеллект Поддержать канал: Boost Канал: Журнал «Движ»


Хлебни ИИ - про искусственный интеллект
OpenAI: Искусственный интеллект чаще генерирует ответы, чем предоставляет точную информацию Компания OpenAI представила новый бенчмарк SimpleQA, предназначенный для оценки достоверности ответов своих и других моделей ИИ. Результаты исследований показали, что даже самый новый и усовершенствованный алгоритм o1-preview достиг всего лишь 42.7% правильных ответов. Это указывает на то, что современные большие языковые модели LLMs чаще дают недостоверные сведения, чем корректные. Конкурирующая модель Claude-3.5-sonnet от компании Anthropic продемонстрировала ещё худшие результаты - всего 28.9% верных ответов. Тем не менее, она чаще признаёт свою неуверенность и отказывается от ответов, что в некоторых случаях может быть разумнее, чем предоставление потенциально ошибочной информации. В исследовании также было отмечено, что модели имеют тенденцию переоценивать свои силы, демонстрируя уверенность в неверных ответах, что усугубляет проблему "галлюцинаций" - выдачи заведомо ложной информации.

TechnoHub Media
Новый ChatGPT оказался хуже Новая модель o1-preview показала ужасные результаты в тесте от OpenAI. Она ответила правильно только на 43% вопросов. Проверяли с помощью теста, который состоит из 4326 вопросов на темы от кино и науки до географии и технологий. На них ИИ должен был точно и уверенно отвечать. Разница в корректных ответах между GPT-4o и o1-preview составила всего 3%. 2 TechnoHub Media


Lama News
OpenAI показала, что LLM выдают ложные ответы в 60% случаев. Компания представила бенчмарк SimpleQA для оценки точности выходных данных ИИ. В нём o1 и Claude 3.5 Sonnet продемонстрировали довольно низкие показатели успешности - 42,7% и 28,9% соответственно. Нейронки - это очень крутой инструмент, но пока переставать думать своей головой рано.


КП Наука
Open AI случайно показала новейшую модель ИИ Сбой? Или аккуратный слив ради промо? Так или иначе. Если на сайте Open AI набрать определенный адрес, попадает на новейшую модель ИИ под названием 01 прощай, GPT 4, ты устарела . Форточка продержалась недолго. Когда все ринулись тестить и пробовать вот только я не понял, как изначально-то узнали, какой адрес набирать , компания закрыла доступ. Версия 01 в пробном варианте разослана по экспертам, которым сказали тестить и не болтать, а тут не пробная, а уже готовая, ого. Отзывы положительные. Пишут, что 01 выдает цепочку рассуждений как очень умный человек. И все-таки галлюцинации случаются. С вами был научный журналист Евгений Арсюхин. – там можно задать мне вопросы Пишем о науке на KP.RU - серьёзно, просто и иногда весело!
Похожие новости












 +1
+1







 +17
+17
OpenAI интегрировала ChatGPT в Excel и Google Sheets для всех пользователей
Технологии
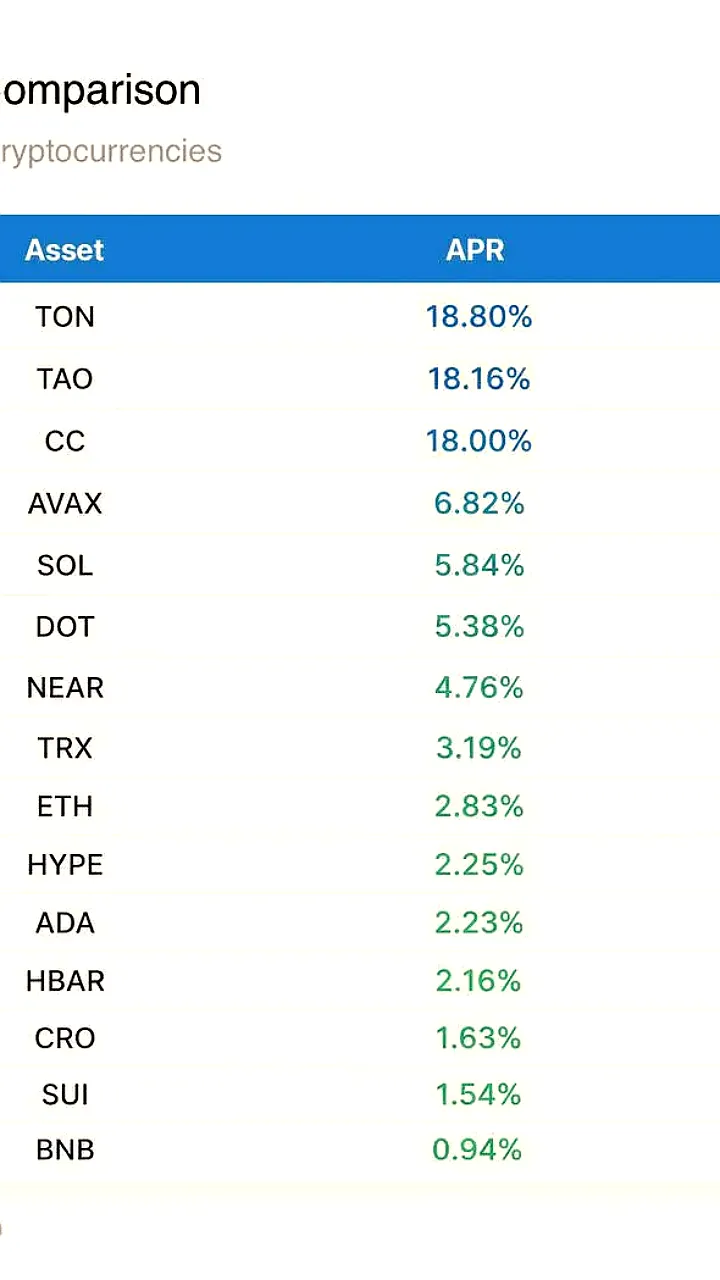
1 день назад Павел Дуров анонсировал успех TON в стейкинге среди криптовалют
Экономика
1 день назад Кремниевая долина нанимает философов для обучения ИИ с зарплатой до 400 тыс. долларов
Общество
1 день назад Telegram запускает казино Emoji Stake с возможностью ставок
Спорт
1 день назад +1Инвестиции в ИИ приводят к снижению свободного денежного потока у американских IT гигантов
Экономика
1 день назад В Италии зафиксирован первый случай лечения зависимости от искусственного интеллекта
Происшествия
1 день назад +17