13 октября, 15:17
Исследование Apple: Нейронные сети не справились с математическими задачами
Ещё по теме

NN
Исследователи из Apple проверили популярные нейронки на реальную способность решать математические задачи. Вывод: восстание машин можно отменять. Даже ChatGPT o1 не смогла построить логические цепочки в нескольких тестах. То, что в OpenAI называют способностью рассуждать, авторы публикации считают просто продвинутой системой воспроизведения паттернов. В тестах участвовали модели ChatGPT, Llama, Phi, Gemma и Mistral. Логикой не обладает ни одна из них.


Техно Радар | Технологии, будущее, web3
Исследование Apple показало, что ИИ-модели не думают, а лишь имитируют мышление Исследователи Apple обнаружили, что большие языковые модели, такие как ChatGPT, не способны к логическому мышлению и их легко сбить с толку, если добавить несущественные детали к поставленной задаче, сообщает издание TechCrunch. #искусственныйинтеллект #иибот #gpt4 #chatgpt


Хайтек+
Исследование Apple показало, что ИИ-модели лишь имитируют мышление Исследование, проведённое учёными Apple, показало, что большие языковые модели, такие как ChatGPT, на самом деле не думают и не рассуждают так, как это делает человек. Несмотря на способности решать простые математические задачи, как выяснили исследователи, БЯМ легко сбить с толку, добавив в задачу лишнюю или несущественную информацию. Это открытие ставит под сомнение способность ИИ к логическому мышлению и выявляет его уязвимости при работе с изменёнными условиями.


iPhones.ru
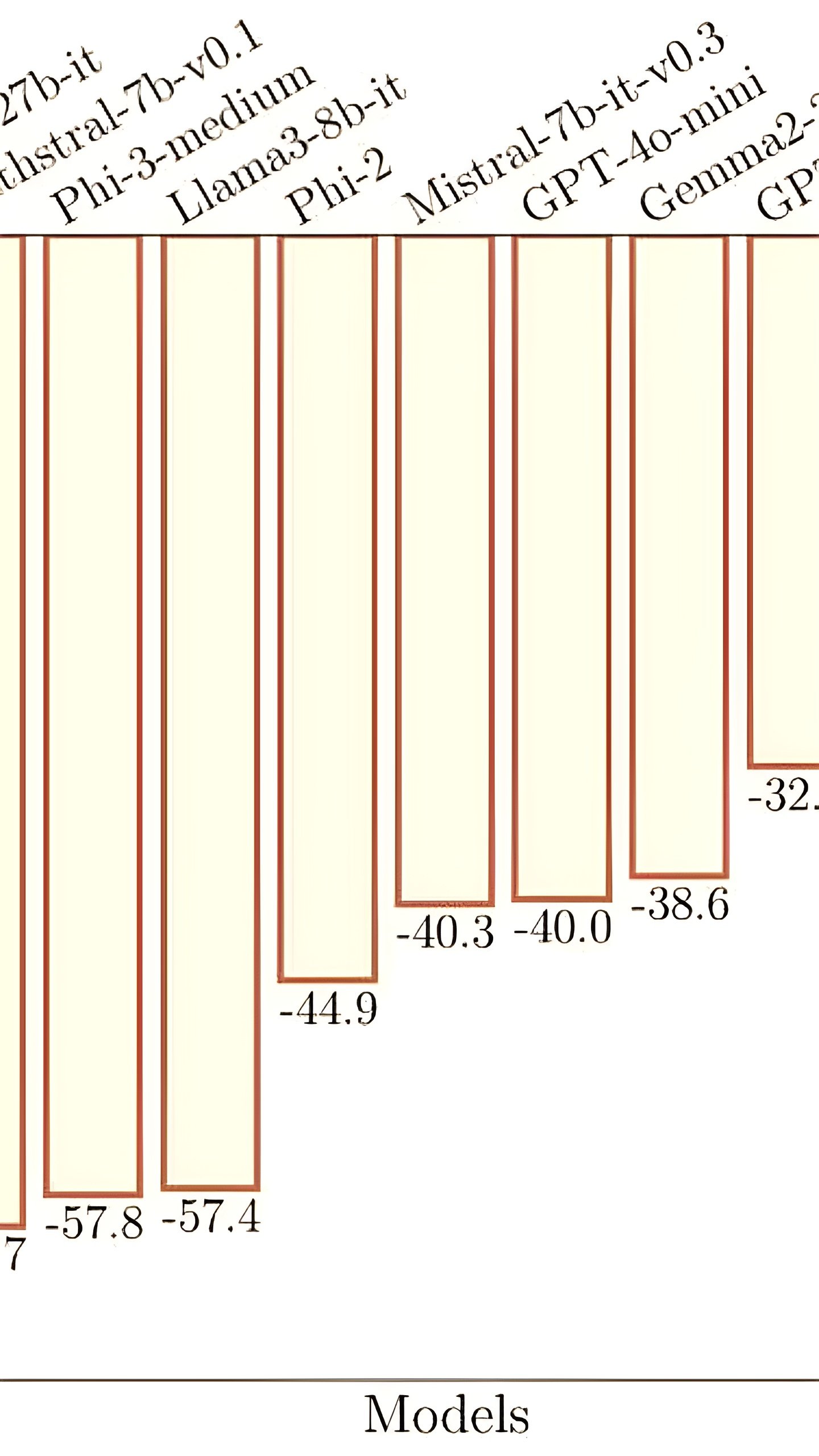
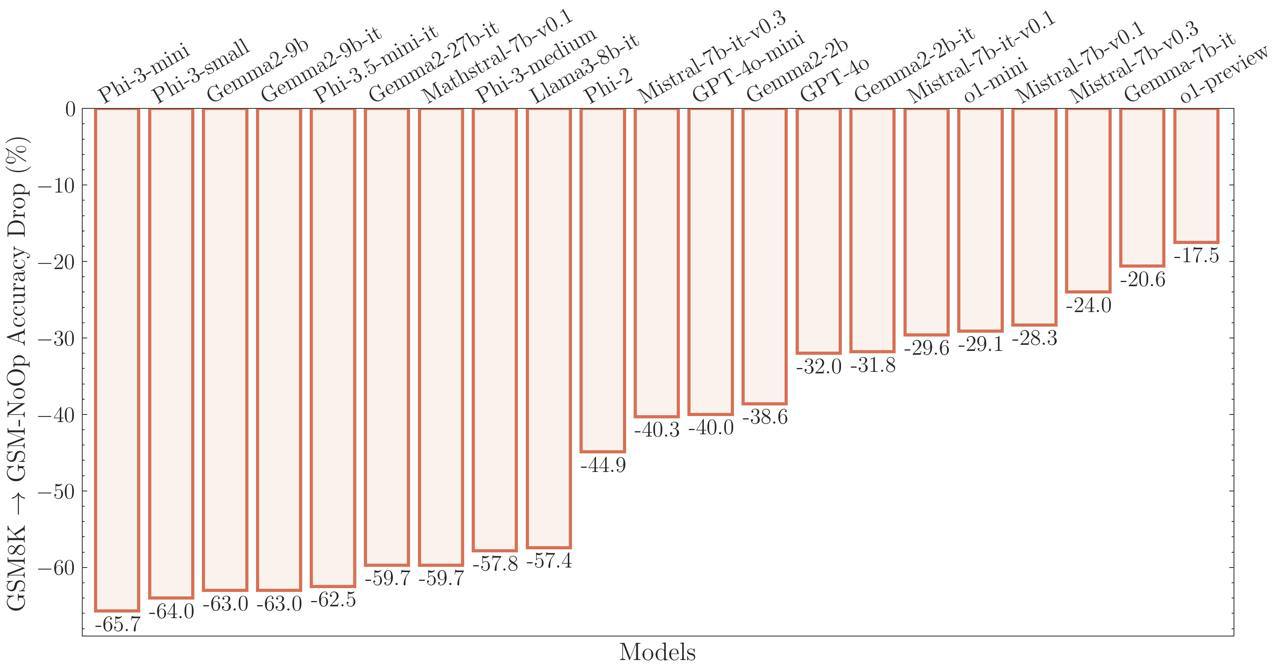
Apple доказала слабое место всех популярных ИИ, в том числе ChatGPT. Они не способны думать Группа ученых из Apple, занимающихся искусственным интеллектом, опубликовала исследование, в котором заявляет, что современные ИИ не способны думать. Чтобы доказать свою теорию, они создали бенчмарк GSM-Symbolic, который измеряет «способность мыслить» различных больших языковых моделей LLM . Согласно выводам исследования, любые, даже незначительные изменения в формулировке запросов, могут привести к существенно отличающимся ответам, что подрывает доверие к моделям. Один из примеров, приведенных в статье, описывает простую математическую задачу о том, сколько киви человек собрал за несколько дней. Когда в условие были включены данные о размере киви, которые не относятся к решению, модели o1 от OpenAI используется в ChatGPT и Llama от Meta изменили ответы, чего не должны были делать. признана экстремистской и запрещена в России #новости


Мир ИТ с Альбертом
Проведённое Apple исследование ведущих языковых моделей – от OpenAI, экстремистской Meta и других компаний — выявило неспособность искусственного интеллекта ИИ «мыслить логически». Например, когда моделям задали задачу посчитать, сколько человек собрал киви за несколько дней и добавили данные о размере нескольких фруктов, модели OpenAI и Meta дали неверный ответ. Время Скайнет пока не пришло...


Блохи в свитере
Исследователи из Apple провели проверку популярных нейронных сетей на их способность решать математические задачи. Результаты показали, что большинство из них, включая ChatGPT, не смогли построить логические цепочки, необходимые для успешного решения задач. Несмотря на успехи в распознавании и воспроизведении паттернов, нейронные сети не обладают настоящей логикой и способностью к рассуждению, как это утверждают некоторые разработчики. В исследовании приняли участие модели, такие как ChatGPT, Llama, Phi, Gemma и Mistral, и ни одна из них не продемонстрировала логического мышления, необходимого для сложных математических операций. Таким образом, опасения о восстании машин можно считать преждевременными — нынешние нейронные сети ещё далеки от настоящего понимания и мышления, как это было продемонстрировано в тестах.

Chad GPT | Нейросети
Исследователи из Apple проверили популярные нейронки на реальную способность решать математические задачи. Вывод: восстание машин можно отменять. Даже ChatGPT o1 не смогла построить логические цепочки в нескольких тестах. То, что в OpenAI называют способностью рассуждать, авторы публикации считают просто продвинутой системой воспроизведения паттернов. В тестах участвовали модели ChatGPT, Llama, Phi, Gemma и Mistral. Логикой не обладает ни одна из них. Нейросети DarkGPT BOT


Мы из будущего
Исследователи ставят под сомнение способность искусственного интеллекта “думать” Исследование Apple показало, что большие языковые модели LLM , такие как ChatGPT, не способны к логическому мышлению, а лишь имитируют его, воспроизводя шаблоны из обучающих данных. Они могут решать простые задачи, но легко сбиваются при добавлении несущественных деталей. Например, если к задаче про количество собранных киви добавить информацию о размере плодов, модель ошибочно вычитает их из общего числа. Это указывает на то, что LLM не понимают суть задач. Хотя правильные результаты можно получить через технику формулировки запросов, для сложных задач потребуется больше данных. Возможно, модели “рассуждают”, но мы еще не понимаем как или не можем контролировать этот процесс. Мы из будущего


Romancev768
Apple выявила слабость ИИ – он не умеет думать Учёные из Apple провели исследование, в ходе которого выявили, что любая малейшая модификация в формулировке запроса приводит к значительным изменениям в ответах ИИ, что ставит под сомнение их надёжность. Особое внимание было уделено тестированию математических задач, где контекстная информация, понятная человеку, но не влияющая на решение задачи, приводила к разным результатам. Среди всех протестированных нейросетей, даже ChatGPT o1, который по словам OpenAI рассуждает перед ответом, изменял свои ответы при наличии дополнительной информации, хотя это не должно было повлиять на результат. В итоге учёные из Apple заключили, что языковые модели не используют логическое мышление для решения проблем, а скорее полагаются на распознавание шаблонов, которые были заложены во время обучения.


Айтишник | Апи | Технологии
Исследователи из Apple проверили популярные нейронки на реальную способность решать математические задачи. Вывод: восстание машин можно отменять. Даже ChatGPT o1 не смогла построить логические цепочки в нескольких тестах. То, что в OpenAI называют способностью рассуждать, авторы публикации считают просто продвинутой системой воспроизведения паттернов. В тестах участвовали модели ChatGPT, Llama, Phi, Gemma и Mistral. Логикой не обладает ни одна из них. Айтишник Подписаться
Похожие новости

 +7
+7








 +4
+4






 +7
+7
OpenAI рассматривает иск против Apple из-за неудачного партнерства
Технологии
1 день назад +7Семья студента подала в суд на OpenAI из-за смертельных советов ChatGPT
Происшествия
1 день назад Threads запускает ИИ-бота Meta AI в пяти странах, пользователи выражают недовольство
Технологии
1 день назад OpenAI интегрировала Codex в мобильное приложение ChatGPT
Технологии
17 часов назад +4Сотрудники крупных компаний используют ИИ для накрутки внутренних метрик
Технологии
23 часа назад Роботы Helix 02 от Figure AI успешно отработали 8-часовую смену на производственной линии
Технологии
1 день назад +7